![[認証情報] パネル](https://cdn.qwiklabs.com/%2FtHp4GI5VSDyTtdqi3qDFtevuY014F88%2BFow%2FadnRgE%3D)
![[別のアカウントを使用] オプションがハイライト表示されている、アカウントのダイアログ ボックスを選択します。](https://cdn.qwiklabs.com/eQ6xPnPn13GjiJP3RWlHWwiMjhooHxTNvzfg1AL2WPw%3D)



始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create BigQuery dataset and tables
/ 20
DML statements (INSERT, UPDATE, DELETE)
/ 20
SQL SELECT statements
/ 10
DDL statements
/ 10
UDFs and stored procedures
/ 20

BigQuery は、データ定義言語(DDL)、データ操作言語(DML)、ユーザー定義関数(UDF)、ストアド プロシージャなど、さまざまな種類の SQL ステートメントをサポートしています。
このラボの目的は、Redshift のプロフェッショナルが BigQuery で SQL の操作を開始するために必要な知識とスキルを習得することです。このラボを完了すると、Redshift のプロフェッショナルは、BigQuery で SQL を使用して BigQuery のデータ構造を作成、更新、操作する方法について、より深く理解できるようになります。
このラボでは、DDL ステートメントを使用してテーブルとビューを作成し、DML ステートメントを使用してテーブルを更新し、SQL を使用してデータを結合し、カスタムのユーザー定義関数(UDF)とストアド プロシージャを定義します。
このラボでは、次の方法について学びます。
SQL SELECT ステートメントを使用して、データを結合し、共通テーブル式(CTE)を定義する。各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
シークレット ウィンドウを使用して Google Skills にログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud コンソールにログインする際に使用します。
[Google コンソールを開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。 他の認証情報を使用すると、エラーや料金が発生します。
利用規約に同意し、再設定用のリソースページをスキップします。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側のパネルには、このラボで使用する必要がある一時的な認証情報が表示されます。
ユーザー名をコピーし、[Google Console を開く] をクリックします。 ラボでリソースが起動し、別のタブで [アカウントの選択] ページが表示されます。
[アカウントの選択] ページで [別のアカウントを使用] をクリックします。[ログイン] ページが開きます。
[接続の詳細] パネルでコピーしたユーザー名を貼り付けます。パスワードもコピーして貼り付けます。
しばらくすると、このタブで Cloud コンソールが開きます。

BigQuery では、データ定義言語(DDL)を使用してデータセットとテーブルを作成できます。また、SQL ステートメント LOAD DATA を使用して、1 つ以上のファイルからデータを新規または既存のテーブルに読み込むこともできます。
DDL ステートメントを使用して BigQuery データセットとテーブルを作成する方法と、LOAD DATA SQL ステートメントを使用してデータを読み込む方法について詳しくは、CREATE SCHEMA ステートメント、CREATE TABLE ステートメント、LOAD DATA ステートメントのドキュメントをご覧ください。
このタスクでは、DDL を使用して BigQuery にデータセットとテーブルを作成し、LOAD DATA ステートメントを使用して新しいテーブルにデータを読み込みます。
 )で、[プロダクト] の [BigQuery] をクリックします。
)で、[プロダクト] の [BigQuery] をクリックします。[Cloud コンソールの BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスには、クイックスタート ガイドとリリースノートへのリンクが表示されます。
[完了] をクリックします。
このクエリは、animals_dataset という名前の新しい BigQuery データセットを作成します。DDL ステートメントでは、SCHEMA という用語はテーブル、ビュー、その他のリソースの論理的なコレクションを指します。これは BigQuery ではデータセットと呼ばれます。
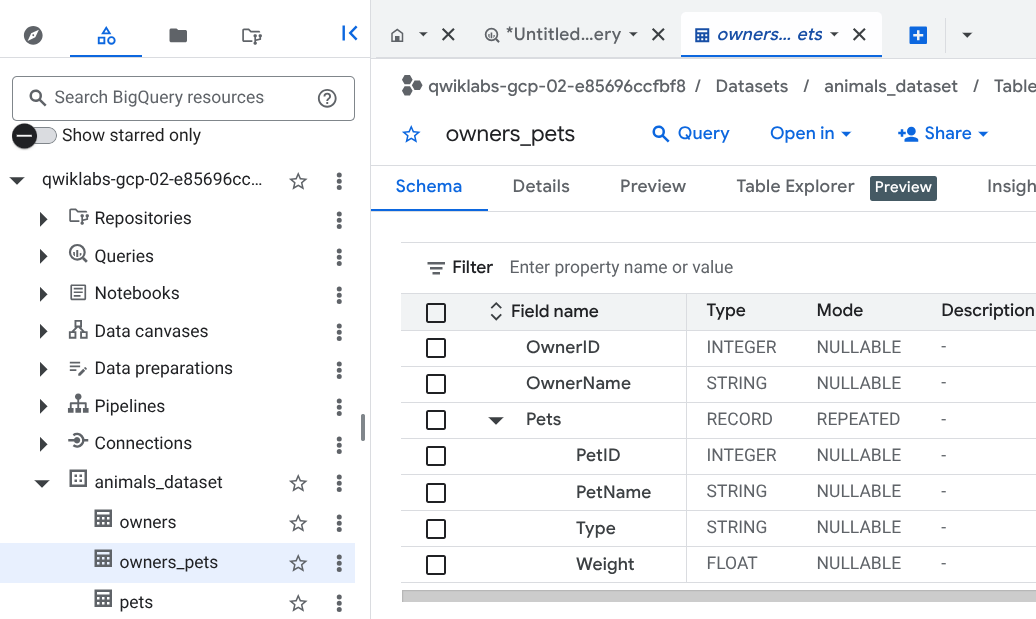
これらのクエリは、先ほど作成した animals_dataset という BigQuery データセットの中に、owners と pets という 2 つのテーブルを作成します。
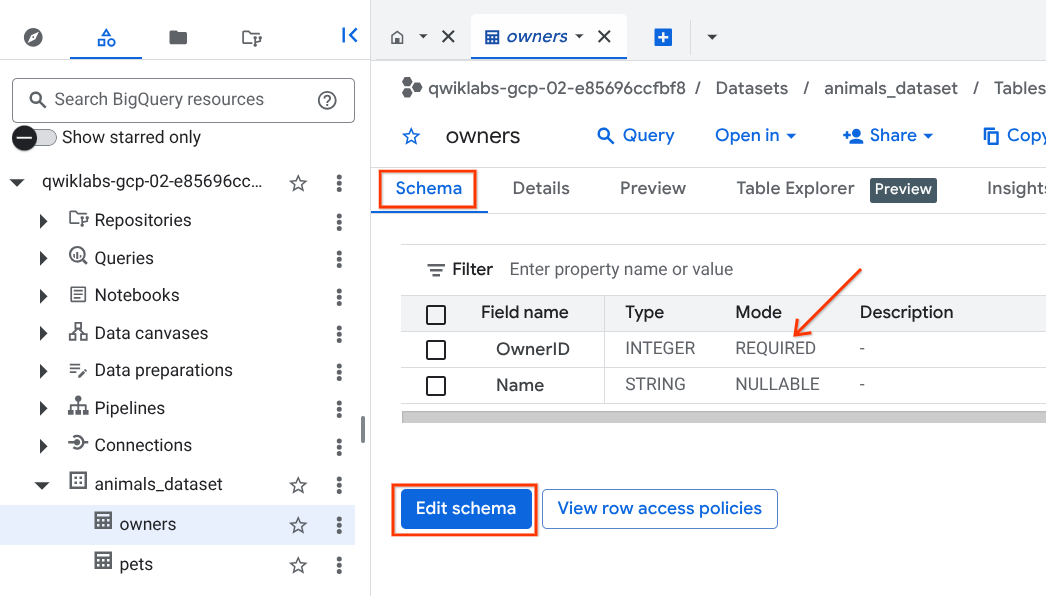
次のステップに進む前に、ステップ 5 でエラーが発生しないように、テーブル スキーマのフィールド モードを REQUIRED から NULLABLE に更新します。
[従来のエクスプローラ] パネルでテーブル名を選択し、[スキーマ] タブを選択して [スキーマの編集] をクリックし、フィールドモードを REQUIRED から NULLABLE に更新します。両方のテーブルでモードが「REQUIRED」となっているすべてのフィールドに対して、この手順を繰り返してください。
これらのクエリは、Cloud Storage の CSV ファイルから owners テーブルと pets テーブルにデータを読み込みます。
[結果] ペインに、LOAD ステートメントが正常に実行されたことを示すメッセージが表示されます。
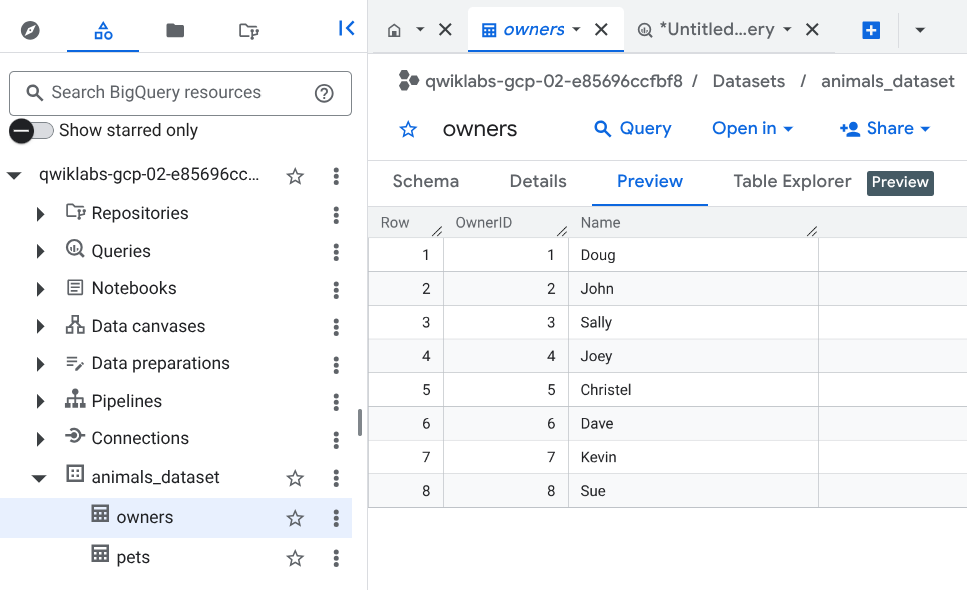
[従来のエクスプローラ] ペインで、データセットを開いてテーブルを表示し、owners テーブルを選択します。
[詳細] タブと [プレビュー] タブをクリックして、テーブルの詳細情報とデータのプレビューを確認します。
[プレビュー] タブのデータを更新するには、[更新](右上)をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
BigQuery では、DML を使用して既存のテーブルのデータを更新できます。これには、BigQuery テーブルのデータの追加、変更、削除が含まれます。
DML ステートメントを使用して BigQuery テーブルのデータを操作する方法について詳しくは、GoogleSQL のデータ操作言語(DML)ステートメントのドキュメントをご覧ください。
このタスクでは、DML を使用して既存の BigQuery テーブルに対してデータの挿入、更新、削除を行います。
各挿入クエリの実行後、[結果] ペインには、pets テーブルに 1 件のレコードが追加されたことが表示されます。
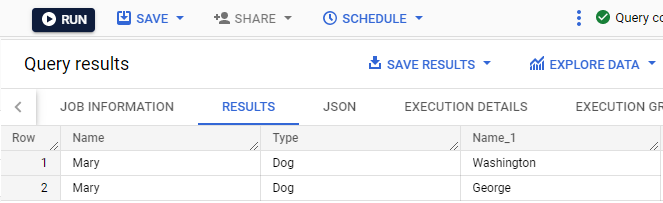
owners テーブルの Mary のレコードが、pets テーブルの 2 匹の飼い犬(George と Washington)のレコードに結合されています。
このステートメントにより、pets テーブル内の 10 行が変更されます。
pets テーブルで、すべての犬が「Canine」と表示されていることを確認します。
[プレビュー] タブのデータを更新するには、[更新](右上)をクリックします。
このステートメントにより、pets テーブルから 1 行が削除されます。
pets テーブルからすべての「Frog」が削除されていることを確認します。
[プレビュー] タブのデータを更新するには、[更新](右上)をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
BigQuery では、SQL SELECT ステートメントで結合、CTE、並べ替え、グループ化、フィルタリング、ピボット、ウィンドウ処理などの構文を使用して、必要なデータを取得できます。
BigQuery テーブルのデータを操作するための SQL SELECT 構文の詳細については、クエリ構文のドキュメントをご覧ください。
このタスクでは、複数のテーブルを結合する JOIN オペレーションと、CTE を定義する WITH 句を含む SQL SELECT ステートメントを記述します。
JOIN を使用した次のクエリを実行し、すべての飼い主とそのペットを抽出します。WHERE 句を加えて実行し、「Canine」のみを抽出します。ORDER BY を加えて実行し、結果を飼い主の名前で並べ替えます。pets テーブルには、犬 10 匹、猫 5 匹、豚 2 匹、カメ 1 匹が含まれています。
Doug という名前の飼い主が最も多くのペットを飼っており、その数は合計 4 匹です。
STRUCT の ARRAY として保存されます。ARRAY_AGG(STRUCT…) 構文は、ネストした繰り返し値として結果を返し、結合された値が明確に整理されるため、データ間の関係を把握しやすくなります。
BigQuery で役立つ SQL のオプションとして、WITH 句を使用して CTE を定義し、別のクエリの結果に対してクエリを行うという方法があります。この構文を使用すると、ネストした SQL ステートメントの使用を避け、コードを読みやすくすることができます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
前のタスクでは、DDL を使用して新しい BigQuery データセットとテーブルを作成しました。BigQuery では、DDL を使用して論理ビューとマテリアライズド ビューを作成することもできます。
DDL ステートメントを使用して BigQuery でビューを作成する方法について詳しくは、論理ビューの概要をご覧ください。
このタスクでは、DDL を使用して新しいテーブル、論理ビュー、マテリアライズド ビューを作成します。
[従来のエクスプローラ] ペインで、データセットを開いてテーブルを表示し、owner_pets テーブルを選択します。
[スキーマ] タブをクリックして、新しく作成された owners_pets という名前のテーブルのスキーマを確認します。
スキーマには、Pets という名前のネストした繰り返しフィールドが含まれています。このフィールドには、それぞれの飼い主が飼っているそれぞれのペットのペット ID、名前、種類、体重が含まれています。
前のタスクでは、owners テーブルと pets テーブルを結合して、飼い主ごとのペット数をカウントするクエリを実行しました。今回は、ネストした繰り返しフィールドにデータが含まれているため、ARRAY_LENGTH 関数を使用して、それぞれの飼い主のペットの数を返すことができます。
[ビューに移動] をクリックします。
[従来のエクスプローラ] ペインで、small_pets ビューの [アクションを表示](縦に並んだ 3 つの点のアイコン)をクリックし、[クエリ] を選択します。
クエリエディタで次のクエリを実行して、ビューのデータを調べます。
BigQuery のマテリアライズド ビューは事前に計算されたビューで、パフォーマンスと効率を向上させるためにクエリの結果を定期的にキャッシュに保存します。マテリアライズド ビューは、集計などの複雑な処理を必要とするクエリで特に役立ちます。
[マテリアライズド ビューに移動] をクリックします。
[従来のエクスプローラ] ペインで、pet_weight_by_type マテリアライズド ビューの [アクションを表示](縦に並んだ 3 つの点のアイコン)をクリックし、[クエリ] を選択します。
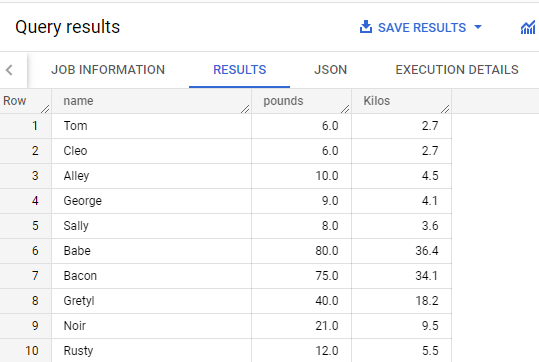
クエリエディタで次のクエリを実行して、マテリアライズド ビューのデータを調べます。
犬の合計重量は最も重く、314 ポンドです。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
BigQuery では、目的の処理を行う組み込み関数が存在しない場合に、カスタム UDF を定義できます。UDF は 1 つ以上の入力列を受け取り、入力に対してアクションを実行し、それらのアクションの結果を出力として返します。また、SELECT や INSERT などの SQL ステートメントのコレクションを任意の順序で実行する関数として、ストアド プロシージャを定義することもできます。
BigQuery での UDF とストアド プロシージャの定義について詳しくは、ユーザー定義関数と SQL ストアド プロシージャを操作するをご覧ください。
このタスクでは、テーブル内の既存の値を再計算し、テーブルに新しいデータレコードを簡単に追加できるようにする UDF とストアド プロシージャを定義します。
新しいペットを簡単に追加できるようにするストアド プロシージャを作成することもできます。次の手順では、pets テーブルで最大のペット ID を検索し、その ID に 1 の値を加算します。次に、その新しい値を新しいペットの ID として割り当てます。新しいペットが追加されると、新しいペット ID の値が返されます。
SELECT * の [結果を表示] をクリックします。関数の出力変数は、Duke という名前の犬に新しく作成されたレコードで、ペット ID が 30 であることに注目してください。
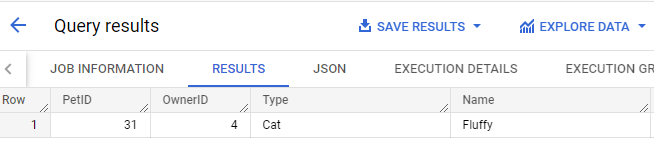
SELECT * の [結果を表示] をクリックします。ID フィールドの値がさらに増えていることに注目してください。Fluffy という名前の猫の新しいペット ID は 31 です。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Skills から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください