

![Compute Engine のデフォルトのサービス アカウント名と編集者のステータスがハイライト表示された [権限] タブページ](https://cdn.qwiklabs.com/1nytD9OUuNUV9undyjUWeOS7LJmekReBDmkUjveCjcU%3D)


始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create Cloud Composer environment
/ 35
Create a Cloud Storage bucket
/ 35
Uploading the DAG to Cloud Storage
/ 30

ワークフローはデータ分析における一般的なテーマのひとつで、データの取り込み、変換、分析によってデータ内で有益な情報を見つけるために使用されます。Google Cloud には、ワークフローをホストするためのツールとして Cloud Composer が用意されています。これは、広く利用されているオープンソース ワークフロー ツールである Apache Airflow のホスト型バージョンです。
このラボでは、Google Cloud コンソールを使用して Cloud Composer 環境を作成し、Cloud Composer を使ってシンプルなワークフローを実行します。このワークフローは、データファイルの存在を確認し、Cloud Dataproc クラスタを作成して Apache Hadoop ワードカウント ジョブを実行した後、クラスタを削除します。
Google Cloud コンソールを使用して Cloud Composer 環境を作成する
Airflow ウェブ インターフェースで DAG(有向非巡回グラフ)を表示して実行する
保存されたワードカウント ジョブの結果を表示する
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
Qwiklabs にシークレット ウィンドウでログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
Google Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。
Google Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールで、右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。
[続行] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続した時点で認証が完了しており、プロジェクトに各自のプロジェクト ID が設定されます。次に例を示します。
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
出力:
出力例:
出力:
出力例:
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] > [ダッシュボード] から確認できます。
編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。729328892908)をコピーします。{project-number} はプロジェクト番号に置き換えてください。Google Cloud コンソールのタイトルバーで、[Cloud Shell をアクティブにする] をクリックします。プロンプトが表示されたら、[続行] をクリックします。
次のコマンドを実行して、Compute デベロッパー サービス アカウントに Composer ワーカー ロールを割り当てます。
このセクションでは、Cloud Composer 環境を作成します。
Google Cloud コンソールのタイトルバーにある検索フィールドに「Composer」と入力し、[プロダクトとページ] セクションの [Composer] をクリックします。
[環境を作成] をクリックして [Composer 3] を選択します。環境を以下のように設定します。
| プロパティ | 値 |
|---|---|
| 名前 | highcpu |
| ロケーション | |
| イメージのバージョン | composer-3-airflow-n.n.n-build.n(注: 利用可能なイメージの中で最も大きい番号のイメージを選択) |
| サービス アカウント | xxxxx-compute@developer.gserviceaccount.com |
| 復元力モード | 標準的な復元力 |
| Airflow データベース ゾーン |
その他の設定はすべてデフォルトのままにします。
コンソールの [環境] ページで、環境の名前の左側に緑色のチェックマークが表示されていれば、環境の作成プロセスは完了しています。
設定が完了するまでには、15~30 分かかることがあります。その間にラボの作業を進めておいてください。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
プロジェクトで Cloud Storage バケットを作成します。このバケットは、Dataproc の Hadoop ジョブの出力として使用されます。
ナビゲーション メニュー > [Cloud Storage] > [バケット] に移動し、[+ 作成] をクリックします。
ユニバーサルに一意の名前(プロジェクト ID 公開アクセスの防止] というメッセージが表示されたら、[確認] をクリックします。
この Cloud Storage バケット名は後ほど Airflow 変数として使用するため、メモしておいてください。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Composer 環境が作成されるまでの間に、Airflow で使用される用語を確認しておきましょう。
Airflow とは、ワークフローの作成、スケジュール設定、モニタリングをプログラムで実行するためのプラットフォームです。
Airflow は、ワークフローをタスクの有向非循環グラフ(DAG)として作成するために使用します。Airflow スケジューラは、指定された依存関係に従って一連のワーカーでタスクを実行します。
有向非巡回グラフとは、実行するすべてのタスクの集まりであり、それらの関係や依存状態を反映するように編成されます。
単一のタスクの記述であり、通常はアトミックです。たとえば、BashOperator は bash コマンドの実行に使用されます。
演算子のパラメータ化されたインスタンスであり、DAG 内のノードです。
タスクの特定の実行であり、DAG、タスク、時点を表します。これには、実行中、成功、失敗、スキップなどの状態があります。
コンセプトの詳細については、基本コンセプトに関するドキュメントをご覧ください。
これから使用するワークフローについて確認しておきましょう。Cloud Composer ワークフローは、DAG で構成されます。DAG は、Airflow の DAG_FOLDER に配置される標準の Python ファイルで定義されます。Airflow は各ファイル内のコードを実行して、動的に DAG オブジェクトをビルドします。任意の数のタスクを記述した DAG を必要なだけ作成できます。一般に、DAG と論理ワークフローが 1 対 1 で対応している必要があります。
以下に、hadoop_tutorial.py ワークフロー コード(DAG とも呼ばれる)を示します。
3 つのワークフロー タスクをオーケストレーションするために、DAG は次の演算子をインポートします。
DataprocCreateClusterOperator: Cloud Dataproc クラスタを作成します。DataprocSubmitJobOperator: Hadoop ワードカウント ジョブを送信し、結果を Cloud Storage バケットに書き込みます。DataprocDeleteClusterOperator: Compute Engine の利用料金が発生しないようにするために、クラスタを削除します。タスクは順番に実行されます。これは、ファイルの次の部分で確認できます。
この DAG の名前は composer_hadoop_tutorial で、1 日に 1 回実行されます。
default_dag_args に渡される start_date が yesterday に設定されているため、Cloud Composer ではワークフローの開始が DAG のアップロード直後に設定されます。
[Composer] に戻り、環境のステータスを確認します。
環境が作成されたら、環境の名前(highcpu)をクリックして詳細を表示します。
[環境の構成] タブで、Airflow ウェブ UI の URL、GKE クラスタ、バケットに保存されている DAG のフォルダへのリンクなどの情報を確認できます。
/dags フォルダ内のワークフローのみです。コンソールで Airflow ウェブ インターフェースにアクセスするには:
Airflow 変数は Airflow 固有のコンセプトであり、環境変数とは異なります。
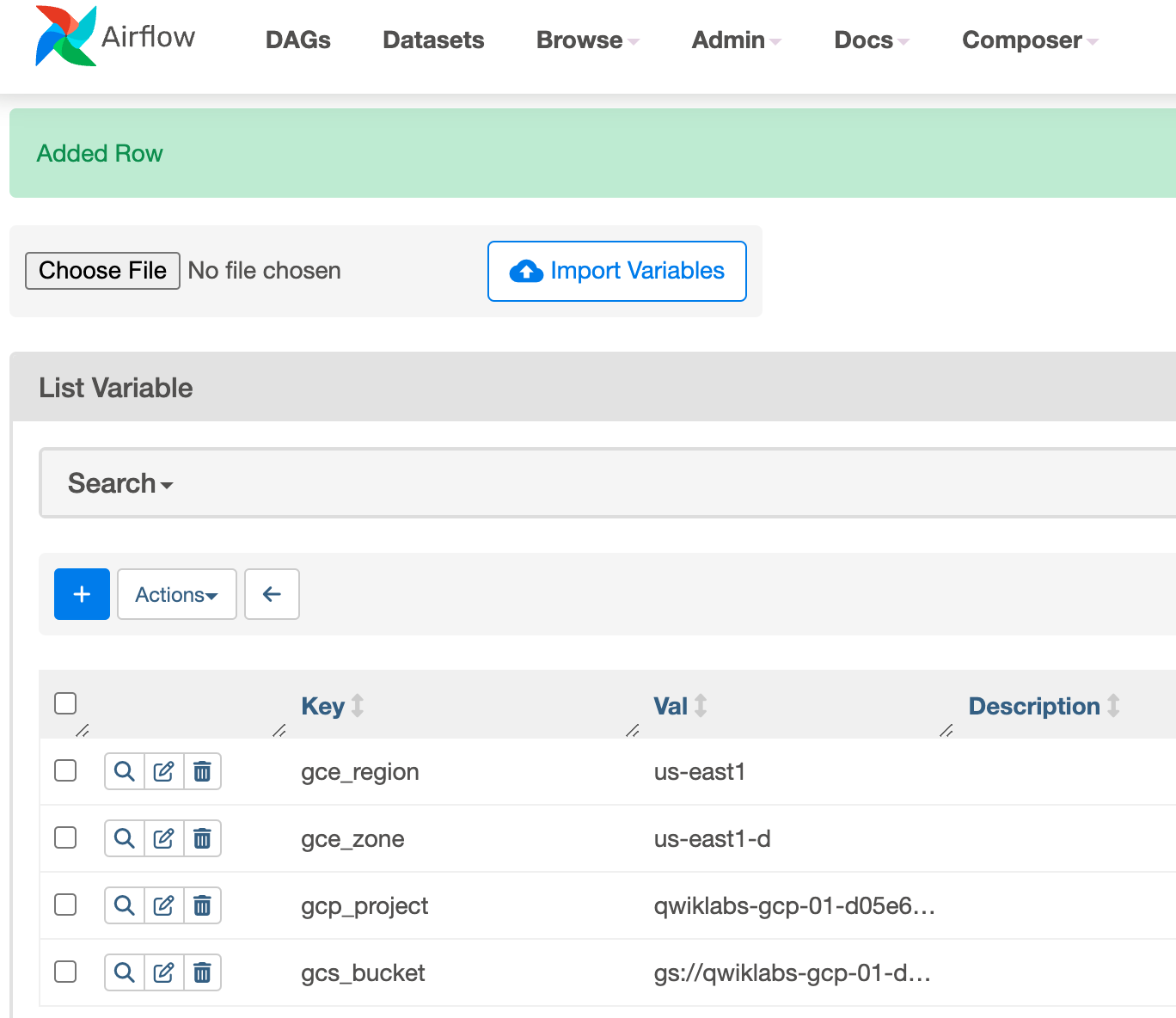
Airflow インターフェースのメニューバーで [Admin] > [Variables] を選択します。
+ アイコンをクリックして新しいレコードを追加します。
| Key | Val | Details |
|---|---|---|
gcp_project |
このラボで使用している Google Cloud Platform プロジェクト。 | |
gcs_bucket |
gs:// |
Dataproc の Hadoop ジョブの出力を保存するバケット。 |
gce_zone |
Cloud Dataproc クラスタを作成する Compute Engine ゾーン。 | |
gce_region |
Cloud Dataproc クラスタを作成する Compute Engine リージョン。 |
[Save] をクリックします。1 つ目の変数を追加したら、2 つ目と 3 つ目の変数でも同じ手順を繰り返します。完了すると、変数テーブルは次のようになります。
DAG をアップロードするには:
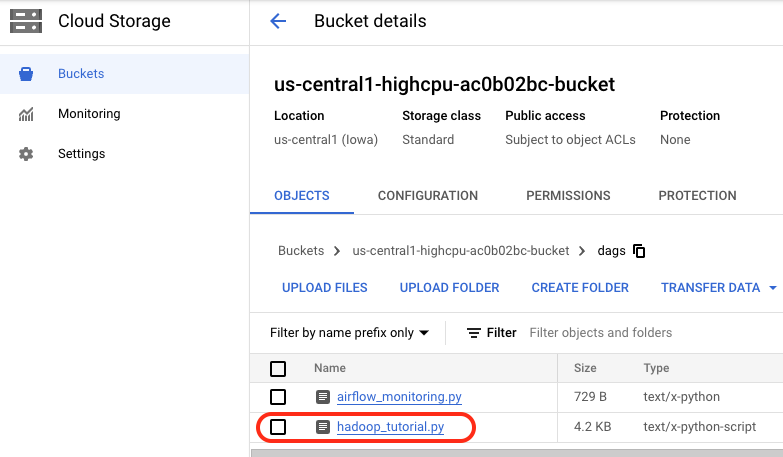
Cloud Shell で次のコマンドを実行し、環境の作成時に自動的に作成された Cloud Storage バケットに hadoop_tutorial.py ファイルのコピーをアップロードします。
次のコマンドの <DAGs_folder_path> を DAG のフォルダへのパスに置き換えます。
DAG のフォルダ] を見つけて、パスをコピーします。ファイルをアップロードするための変更後のコマンドは、次のようになります。
dags フォルダを開くと、[バケットの詳細] の [オブジェクト] タブが表示されます。DAG ファイルが DAG のフォルダに追加されると、Cloud Composer によって DAG が Airflow に追加され、自動的にスケジュールが設定されます。DAG の変更は 3~5 分以内に行われます。
composer_hadoop_tutorial DAG のタスク ステータスは、Airflow ウェブ インターフェースで確認できます。
注: インターフェースに「The scheduler does not appear to be running...」などのメッセージが表示されても無視してかまいません。 Airflow ウェブ インターフェースは、DAG の進行状況に応じて更新されます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
DAG ファイルを Cloud Storage の dags フォルダにアップロードすると、ファイルが Cloud Composer によって解析されます。エラーが見つからなかったら、このワークフローの名前が DAG のリストに表示され、ワークフローがすぐに実行されるようキューに追加されます。
必ず、Airflow ウェブ インターフェースの [DAGs] タブを開いておきます。このプロセスが完了するまでには数分かかります。ブラウザを更新して、最新情報が表示されるかどうかを確認してください。
Airflow で composer_hadoop_tutorial をクリックして DAG の詳細ページを開きます。このページには、ワークフローのタスクと依存関係がいくつか示されています。
ツールバーで [グラフ] をクリックします。各タスクのグラフィックにカーソルを合わせると、そのタスクのステータスが表示されます。タスクを囲む線の色もステータスを表しています(緑は実行中、赤は失敗など)。
[更新] をクリックして最新情報を表示すると、プロセスを囲む線の色がステータスに応じて変わるのを確認できます。
create_dataproc_cluster のステータスが [実行中] に変わったら、ナビゲーション メニュー > [Dataproc] に移動して次の操作を行います。
Dataproc のステータスが [実行中] になったら、Airflow に戻って [更新] をクリックすると、クラスタが完成したことを確認できます。
run_dataproc_hadoop プロセスが完了したら、ナビゲーション メニュー > [Cloud Storage] > [バケット] に移動し、バケット名をクリックして wordcount フォルダでワードカウントの結果を確認します。
Cloud Composer ワークフローを実行しました。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください