

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create the cloud resources
/ 30
Retrieve the Python files and configure them
/ 20
Generate synthetic data and run the pipeline
/ 30
Verify the results in BigQuery
/ 20

あなたは Cymbal Gaming のデータ エンジニアとして、開発チームとともに新しい e スポーツゲーム「Galactic Grand Prix」の開発に携わっています。このゲームでは、異なるチームに属する 2 人のプレーヤーの対戦に基づいてリアルタイムのデータが生成されます。たとえば、1 つのイベントで 2 人のプレーヤーが競い合い、勝者が決まると勝者とチームにポイントが与えられます。あなたは、このストリーミング データを処理するソリューションを構築するよう依頼されました。Dataflow パイプラインを利用して、Pub/Sub からデータを取り込み、Python コードを使用して変換し、結果を BigQuery テーブルに保存します。これらのテーブルを使用して、結果をプレーヤーとチームのダッシュボードとして可視化します。
あなたは、このようなユースケースには、Pub/Sub、Dataflow、BigQuery を使用できることを知りました。また、新しいクエリの記述に行き詰まったときに、Code Assist を使用してコードのレビューとデバッグを行えるなど、Gemini がさまざまな場面で役立つことも学びました。問題の解決に役立つ提案もしてくれます。これらの機能を使用すれば、もっと自立して取り組めるようになり、おそらくは効率も向上するはずです。しかし、何から始めればよいかわかりません。
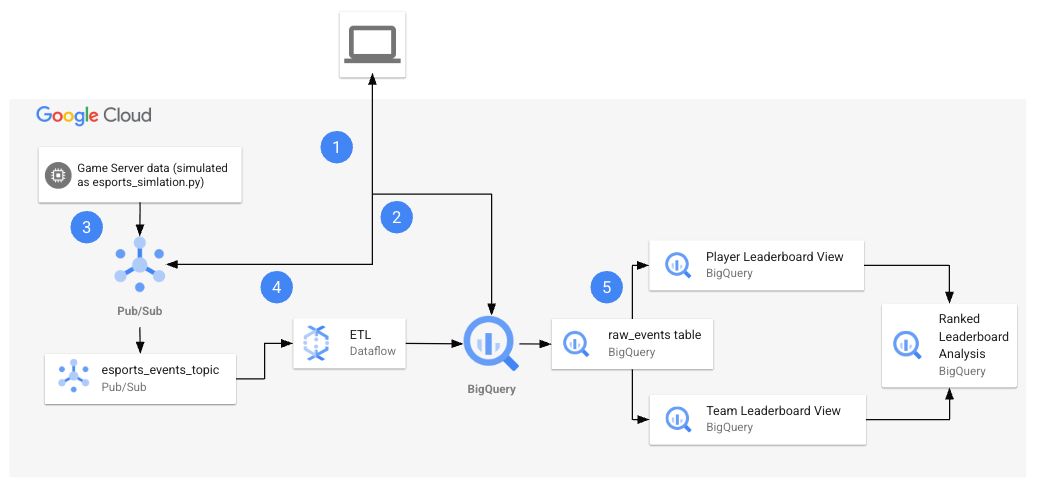
ラボを開始すると、次の図に示すリソースが含まれる環境が提供されます。
ラボを終えるまでに、このアーキテクチャを使用して複数のタスクを実行します。
次の表で、ラボのアーキテクチャに含まれる各タスクについて詳しく説明します。
| タスクの番号 | 詳細 |
|---|---|
| 1. | Cloud Shell で環境変数を構成します。 |
| 2. |
クラウド リソースの作成: Cloud Shell コマンドを使用して、Pub/Sub トピックとサブスクリプション、および BigQuery データセットを作成します。 |
| 3. |
リポジトリから Python ファイルを取得する: このタスクでは、リポジトリから Python ファイルを取得し、プロジェクト用に構成します。 |
| 4. |
合成データを生成してパイプラインを実行する: プロジェクト用に Python ファイルを構成したら、ファイルを実行して合成データを生成し、パイプラインを開始します。esports-simulation.py ファイルは、Python を使用してゲームイベントの Pub/Sub メッセージを継続的に生成します。その後、esports-pipeline.py ファイルを実行できます。このファイルを実行すると、メッセージを取り込み、変換し、結果を BigQuery の raw_events、player score updates、team score updates の各テーブルに記録する Dataflow パイプラインが起動します。 |
| 5. |
BigQuery で結果を確認する: データの使用と変換が完了し、レコードが BigQuery のテーブルに書き込まれたので、結果を確認します。各テーブルに対してクエリを実行し、結果を分析して表示します。 |
このラボでは、次の方法について学びます。
最後に、このラボで学んだ内容を振り返る時間が用意されています。ストリーミング データを使用して独自のユースケースにどのように対処できるか検討し、ラボジャーナルの質問に答えましょう。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

このタスクでは、Cloud Shell で環境変数を構成します。
Cloud Shell を開きます。
このラボで Cloud Shell を初めて使用するため、使用を承認する必要があります。ポップアップ ウィンドウで [承認] をクリックして使用を承認してください。
次のコマンドを実行します。
以下のコマンドを実行して、変数が保存されていることを確認します。
このタスクでは、Cloud Shell を使用して、Pub/Sub トピックとサブスクリプション、BigQuery データセットなどのクラウド リソースを作成します。
Cloud Shell を開いたまま、次の操作を行います。
次のコマンドを実行して、Pub/Sub トピックを作成します。
次のコマンドを実行して、Pub/Sub サブスクリプションを作成します。
次のコマンドを実行して、BigQuery データセットを作成します。
コンソールの上部には検索機能があります。ここに「Pub/Sub」と入力し、表示されたオプションから [Pub/Sub] をクリックします。esports_events_topic を含む Pub/Sub トピックが一覧表示されます。
トピック ID である esports_events_topic をクリックします。トピックの [サブスクリプション] タブが表示され、esports_events_topic-sub サブスクリプションが一覧表示されます。これで、トピックとサブスクリプションが正常に作成されたことを確認できます。
コンソールの上部にある検索機能に戻ります。ここに「BigQuery」と入力し、表示されたオプションから [BigQuery] をクリックします。[BigQuery Studio へようこそ] ページが表示され、[Cloud コンソールの BigQuery へようこそ] ポップアップが表示されます。
[完了] をクリックします。
[エクスプローラ] ペインで、プロジェクトを開きます。
リストの下部に esports_analytics データセットが表示されます。これで、BigQuery データセットが正常に作成されたことがわかります。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
次に、Cloud Shell で wget を使用して、一般公開の Cloud Storage バケットから Python ファイルを取得します。ファイルを取得したら、Cloud Shell エディタでファイルを開き、Gemini の Code Assist 機能を使用して各ファイルの内容を解説してもらいます。最後に、Cloud Shell エディタを使用して、プロジェクトと Cloud Storage バケットの詳細をファイルに落とし込んで構成します。
Cloud Shell に戻ります。
次のコマンドを実行して、ホーム ディレクトリに戻ります。
esports ディレクトリを作成し、そのディレクトリに移動します。
以下の wget コマンドを使用して Python ファイルを取得します。
ファイルがダウンロードされたことを示す確認メッセージがターミナルに表示されます。
Cloud Shell で [エディタを開く] ボタンをクリックします。Cloud Shell エディタが開きます。Gemini Code Assist ペインも表示されます。
チュートリアルのタブを閉じます。
[エクスプローラ] ペインで、esports フォルダを開きます。Python ファイルが表示されます。
esports-simulation.py ファイルを開きます。
ファイルの右上にある Gemini 
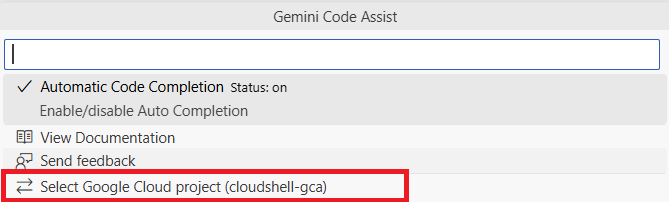
[Select Gemini Code Assist Project] をクリックして、Gemini で使用するプロジェクトを選択します。リストから
Gemini Code Assist ペインの下部には、プロンプトを入力する場所があり、[Gemini に相談] と表示されています。次のプロンプトを入力します。
Code Assist がコードの内容を詳しく説明してくれます。大まかに言うと、e スポーツの試合イベントをシミュレートし、それらを Google Cloud Pub/Sub トピックに公開するという流れです。
同じプロセスを使用して、このプロンプトで esports-pipeline.py ファイルが何を行うかを説明します。
自分の言葉で、esports-pipeline.py ファイルが何をするのか説明してみましょう。
データとユースケースを考慮して、Dataflow パイプラインを使用して Pub/Sub メッセージを使用し、その中のデータを変換して結果を BigQuery に保存する方法を考えてください。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
esports-pipeline.py ファイルを開いたままにしておきます。
11 行目付近にある PROJECT_ID 変数を実際のプロジェクト ID に設定します。これは Google Cloud コンソールの最上部に表示されます。または、以下のコードでこの行を置き換えることもできます。
18 行目付近で、GCS_TEMP_LOCATION 変数を Cloud Storage バケット名(起動時に提供されたバケット名)に設定します。結果として、行は次のようになります。
19 行目付近で、REGION 変数をラボのデフォルト リージョンに設定します。これはラボパネルの詳細で確認できます。または、次のコードで置き換えることもできます。
ファイルを保存します。
esports-simulation.py ファイルに戻ります。
10 行目付近で、PROJECT_ID 変数を自分の Project_ID に設定します。他のファイルと同様に、行を以下のコードに置き換えるだけです。
ファイルを保存します。
このタスクでは、Python ファイルを実行して合成データを生成し、パイプラインを実行します。
Cloud Shell ターミナルに戻ります。
ホーム ディレクトリにいることを確認します。
esports ディレクトリに移動します。
pip を使用して依存関係(特に Pub/Sub の Python ライブラリ)をインストールします。
シミュレータを実行します。このスクリプトは継続的に実行され、イベントが Pub/Sub トピックに送信されます。
ターミナルに、イベントがパブリッシュされていることを示す出力が表示されます。このターミナルは開いたままにしておきます。
コンソールの上部にある検索機能を使用します。今回は、Pub/Sub を検索し、リストで [Pub/Sub] をクリックします。
トピック ID である esports_events_topic をクリックします。トピックの [サブスクリプション] タブが表示され、esports_events_topic-sub サブスクリプションが一覧表示されます。
サブスクリプション ID である esports_events_topic-sub をクリックします。
esports_events_topic-sub サブスクリプションの詳細ページで、[メッセージ] タブをクリックします。「[pull] をクリックすると、メッセージが表示され、他のサブスクライバーへのメッセージ配信が一時的に延期されます。」というメッセージが表示されます。
[Pull] をクリックします。ここにメッセージが表示されていれば、esports-simulation.py ファイルによって生成されたメッセージが Pub/Sub で受信されていることが確認できます。[View contents] ボタンを使用して、メッセージのいずれかを自由に確認してください。
新しい Cloud Shell タブを開きます。Cloud Shell ターミナルバーの + アイコンをクリックして、2 つ目のターミナルを開きます。
ホーム ディレクトリにいることを確認します。
esports ディレクトリに移動します。
Dataflow 用の Python 依存関係(apache-beam)をインストールします。新しいターミナルで、仮想環境を設定し、必要なライブラリをインストールします。
Dataflow パイプラインの起動を試みます。以下のコマンドを使用して、パイプライン スクリプトを実行します。この新しいターミナルでも、PROJECT_ID 環境変数と BUCKET_NAME 環境変数が設定されていることを確認してください。
このコマンドは、ジョブを Dataflow サービスに送信します。ジョブが起動してデータの処理を開始するまで数分かかります。
ただし、この時点で、以下のような警告とエラーが表示されます。
ヘルプ 最初に、警告を見ていきましょう。
この警告は、このラボで使用するバケット
エラーについて 次に、エラーに対処しますが、これは何を意味するでしょうか。
このエラーには 2 つの原因が考えられます。
Dataflow API が有効になっていません。ただし、このラボの開始時にこの機能は有効になっています。これは、[API とサービス] に移動すると確認できます。
エラーの実際の原因は、Cloud Compute のサービス アカウントに Cloud Dataflow サービス エージェントのロールを追加する必要があることです。このタスクを完了するための手順は以下のとおりです。
コンソールの上部にある検索機能を使用します。Cloud Storage を検索し、リストの [Cloud Storage] オプションをクリックします。[概要] ページが表示されます。
[バケット] をクリックします。[バケット] ページが表示され、
[保護] をクリックします。オプションのリストが表示され、その中に [削除(復元可能)ポリシー(データ復旧用)] が含まれています。
[無効にする] をクリックします。[削除(復元可能)ポリシーを無効にする] のポップアップが表示されます。
[確認] をクリックします。削除(復元可能)ポリシーが無効になりました。
コンソールの上部にある検索機能を使用して、IAM に移動します。[IAM] ページが表示されます。
[サービス アカウント] をクリックします。サービス アカウントのリストが表示されます。リストされているサービス アカウントの 1 つが Compute Engine 用です。Compute Engine サービスのサービス アカウントは、次のようになります。
このサービス アカウントに Cloud Dataflow サービス エージェントのロールを追加するには、まずその横にある [アクション] をクリックします。
表示されたオプションのリストから [権限を管理] をクリックします。
[サービス アカウント権限の管理] で、[アクセスを管理] をクリックします。編集者ロールがすでに含まれていることを確認してください。
[+ 別のロールを追加] をクリックします。
[ロールを選択] オプションを使用します。[Cloud Dataflow サービス エージェント] ロールを検索して選択します。
[保存] をクリックします。
ロールが追加されたことを確認します。
Cloud Shell に戻ります。
2 つ目のターミナルタブ、つまり Dataflow パイプライン(esports-pipeline.py)を実行するためのタブにいることを確認します。
次のコマンドをもう一度実行します。
今回は、「Dataflow Streaming Engine の自動スケーリングが有効になっています。maxNumWorkers が指定されていない場合、ワーカーは 1~100 の間でスケーリングされます。」というメッセージが表示されます。
これで、削除(復元可能)の警告と Cloud Dataflow サービス エージェントのエラーを解決できました。
コンソールの上部にある検索機能を使用して、Dataflow サービスを検索して選択します。[ジョブ] ページが表示され、同じ名前のジョブが 2 つあります。1 つは実行中で、もう 1 つは失敗しています。
実行中のジョブをクリックします。ジョブグラフが表示されます。ページの下部に [ログ] ペインが表示されます。
[ログ] ペインを展開します。[ジョブのログ] と [ワーカーログ] のタブが表示されます。
[ワーカーログ] をクリックします。
ここで提供されているログを確認します。raw_events、player_score_updates、team_score_updates の各テーブルが作成されたことを示すログが表示されたら、次のタスクに進みます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクでは、SQL クエリを実行して、処理されたメッセージの結果を確認します。これを実現するために、2 つのビューを作成し、それらのビューにクエリを実行して、プレーヤーとチームのリーダーボードを表示します。また「振り返りの時間」セクションでは、リーダーボードをより見やすくするために Looker をどのように活用できるかについて検討します。
BigQuery に戻ります。
エクスプローラでプロジェクトを開き、esports_analytics データセットを選択します。
[+](プラス)をクリックして、新しいクエリを作成します。
[クエリ] タブに次のクエリを入力します。
このクエリは、プレーヤーのリーダーボードとチームのリーダーボードの 2 つのビューを作成します。選手とチームの最新のスコアを検索し、それに応じてランク付けします。
プラスボタンをクリックして、新しいクエリを作成します。
[クエリ] タブに次のクエリを入力します。
プラスボタンをクリックして、新しいクエリを作成します。
[クエリ] タブに次のクエリを入力します。
ジャーナルを使って、次の質問に答えてください。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Python スクリプトから生成されたシミュレートされたデータを使用して、Pub/Sub トピックとサブスクリプション、BigQuery データセット、テーブルとビュー、パイプライン自体など、e スポーツの Dataflow パイプラインをサポートする Google Cloud リソースを生成しました。また、Code Assist を使用して、これらのスクリプトのコードを説明しました。Google Cloud を日々使いこなす中で、Gemini を使用してデータ エンジニアリングのワークフローに関する知識やスキルを深めていきましょう。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2025 年 8 月 11 日
ラボの最終テスト日: 2025 年 8 月 11 日
Copyright 2025 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください