
始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Explore transfers between parent, sub-agent, and peer agents
/ 25
Use session state to store and retrieve specific information
/ 25
Begin building a multi-agent system with a SequentialAgent
/ 25
Add a LoopAgent for iterative work
/ 25
Explore transfers between parent, sub-agent, and peer agents
/ 25
Use session state to store and retrieve specific information
/ 25
Begin building a multi-agent system with a SequentialAgent
/ 25
Add a LoopAgent for iterative work
/ 25
このラボでは、Google Agent Development Kit(Google ADK)内でマルチエージェント システムをオーケストレーションする方法について説明します。
このラボは、以下のラボで取り上げた ADK の基本とツールの使い方を理解していることを前提としています。
このラボでは、次の作業を行います。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

Agent Development Kit は開発者をサポートし、生成モデルからより信頼性が高く洗練された、複数ステップの行動を導き出すことを可能にします。長く複雑なプロンプトを書いたものの期待する結果を確実に引き出せない、という状況に陥る代わりに、複数のシンプルなエージェントを作成し、タスクと責任を分担して連携させて、複雑な問題に協力して取り組めるフローを構築することができます。
このアーキテクチャ アプローチには重要なメリットがいくつかあります。
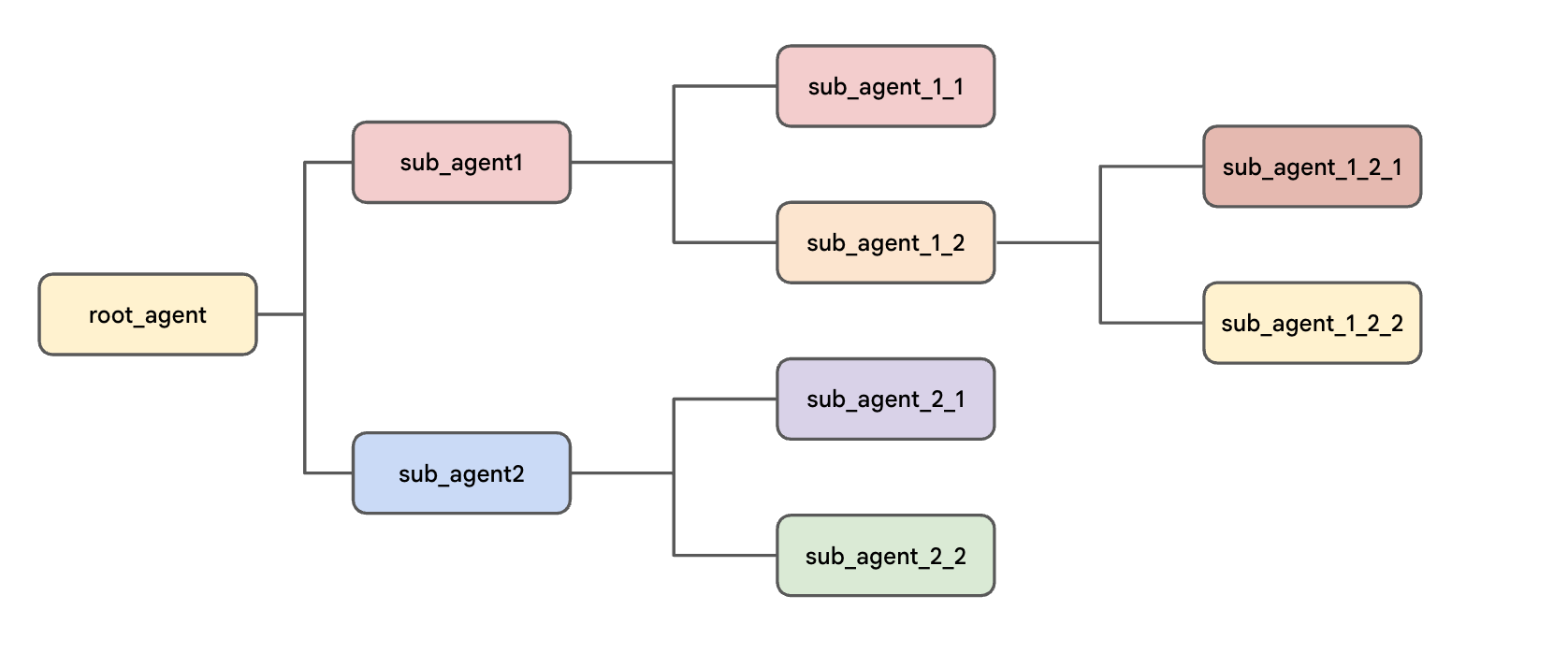
Agent Development Kit では、エージェントをツリーのような構造で編成します。これは、ツリー内の各エージェントの転送オプションを制限し、ツリー内で会話が通過する可能性のあるルートの制御と予測をしやすくするためです。階層構造には、次のようなメリットがあります。
この構造は常に、root_agent 変数で定義されるエージェントから始まります(ただし、ユーザー向けの名前は異なる場合があります)。root_agent は、1 つ以上のサブエージェントの親として機能する場合があります。各サブエージェント エージェントは、独自のサブエージェントを持つことができます。
このラボ環境では、Vertex AI API が有効になっています。ご自身のプロジェクトで以下の手順を行う場合は、Vertex AI に移動し、プロンプトに沿って有効にしてください。
次のコマンドを Cloud Shell ターミナルに貼り付けて、このラボのコードファイルを Cloud Storage バケットからコピーします。
Cloud Shell ターミナルで次のコマンドを実行して、PATH 環境変数を更新し、ADK とその他の要件をインストールします。
会話は常に、root_agent 変数として定義されたエージェントから始まります。
親エージェントのデフォルトの動作は、各サブエージェントの description を理解し、会話の制御をサブエージェントに転送する必要があるかどうかを判断することです。
親エージェントの instruction で、サブエージェントを名前(変数名ではなく、name パラメータの値)で参照することで、この転送をガイドできます。次に例を示します。
Cloud Shell ターミナルで、次のコマンドを実行して .env ファイルを作成し、parent_and_subagents ディレクトリ内のエージェントを認証します。
次のコマンドを実行して、その .env ファイルを workflow_agents ディレクトリにコピーします。このディレクトリはラボの後半で使用します。
Cloud Shell エディタのファイル エクスプローラ ペインで、adk_multiagent_systems/parent_and_subagents ディレクトリに移動します。
agent.py ファイルをクリックして開きます。
3 つのエージェントがあることに注目します。
steering という名前が付いています。ユーザーに質問をして(旅行先はもう決まっているか、それとも旅先選びのアドバイスが必要か)、ユーザーの回答に基づいて 2 つのサブエージェントのうちどちらに会話を誘導するかを判断します。このエージェントには簡単な instruction しかなく、サブエージェントには触れていませんが、サブエージェントの説明の存在は認識されています。root_agent の作成コードに次の行を追加して、travel_brainstormer と attractions_planner を root_agent のサブエージェントにします。
ファイルを保存します。
サブエージェントには、対応する parent パラメータを追加しない点に注意してください。階層ツリーは、親エージェントを作成するときに sub_agents を指定するだけで定義されます。
Cloud Shell ターミナルで次のコマンドを実行して、ADK コマンドライン インターフェースを使用してエージェントとチャットします。
[user]: プロンプトが表示されたら、エージェントに次のように挨拶します。
出力例(実際のものとは異なる場合があります):
エージェントに次のように伝えます。
出力例(実際のものとは異なる場合があります):
応答の角かっこ内の名前 [travel_brainstormer] から、root_agent(名前は [steering])が、サブエージェントの description のみに基づいて、会話を適切なサブエージェントに転送したことがわかります。
user: プロンプトで「exit」と入力して会話を終了します。
どのような場合にどのサブエージェントに転送するかについて、instruction に詳細な指示を含めてエージェントに提供することもできます。たとえば、agent.py ファイルの root_agent の instruction に、次の行を追加してみましょう。
ファイルを保存します。
Cloud Shell ターミナルで、次のコマンドを実行してコマンドライン インターフェースを再度起動します。
エージェントに次のように挨拶します。
エージェントの挨拶に次のように返答します。
出力例(実際のものとは異なる場合があります):
別のサブエージェント attractions_planner に転送されたことがわかります。
次のように返答します。
出力例(実際のものとは異なる場合があります):
今度は travel_brainstormer エージェントに転送されたことがわかります。これは attractions_planner のピア エージェントで、ピア間の転送はデフォルトで許可されています。ピアへの転送を禁止する場合は、attractions_planner エージェントの disallow_transfer_to_peers パラメータを True に設定します。
ユーザー プロンプトで「exit」と入力してセッションを終了します。
root_agent とし、2 番目のステップのエージェントをサブエージェント 1 つだけにして、後続のステップをすべて前のステップのエージェントの唯一のサブエージェントにするというパターンを利用できます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ADK の各会話は、会話に関与するすべてのエージェントがアクセスできる Session 内に含まれます。セッションには会話履歴が含まれており、エージェントはこれをコンテキストの一部として読み取り、応答を生成します。セッションにはセッションの状態の辞書も含まれています。これを使用すると、特に強調したい重要な情報と、その情報へのアクセス方法をきめ細かく制御できます。
セッションの状態は、エージェント間で情報を渡したり、タスクリストなどの単純なデータ構造をユーザーとの会話中に維持したりするのに特に役立ちます。
状態への追加と読み取りを試してみましょう。
adk_multiagent_systems/parent_and_subagents/agent.py ファイルに戻ります。
# Tools ヘッダーの後に次の関数定義を貼り付けます。
このコードでは、次の点に注意してください。
ToolContext として渡されます。必要なのはセッションを受け取るパラメータを割り当てる作業で、それが tool_context という名前のパラメータで示されています。これにより、tool_context を使用して会話履歴(tool_context.events)やセッション状態辞書(tool_context.state)などのセッション情報にアクセスできます。ツール関数によって tool_context.state ディクショナリが変更されると、それらの変更はツールが実行を完了した後にセッションの状態に反映されます。エージェントの作成時に tools パラメータを追加して、ツールを attractions_planner エージェントに追加します。
attractions_planner エージェントの既存の instruction に、次の箇条書きを追加します。
中かっこで囲まれている { attractions? } に注目してください。これはキー テンプレートと呼ばれ、状態辞書から attractions キーの値を読み込む ADK 機能です。attractions キーの後の疑問符は、このフィールドがまだ存在しない場合にエラーが発生するのを防ぐためのものです。
次に、ウェブ インターフェースからエージェントを実行しましょう。このインターフェースには、セッション状態に加えられた変更を確認できるタブがあります。次のコマンドを使用して Agent Development Kit ウェブ UI を起動します。
出力
ウェブ インターフェースを新しいタブで表示するには、ターミナルの出力にある http://127.0.0.1:8000 リンクをクリックします。
新しいブラウザタブが開き、ADK 開発 UI が表示されます。
左側の [Select an agent] プルダウンから、[parent_and_subagents] エージェントを選択します。
「hello」と挨拶して会話を始めます。
エージェントが挨拶したら、次のように返答します。
attractions_planner に転送され、観光スポットのリストが表示されます。
たとえば、次の観光スポットを選択します。
「Okay, I've saved The Sphinx to your list. Here are some other attractions...」のような確認応答が返されます。
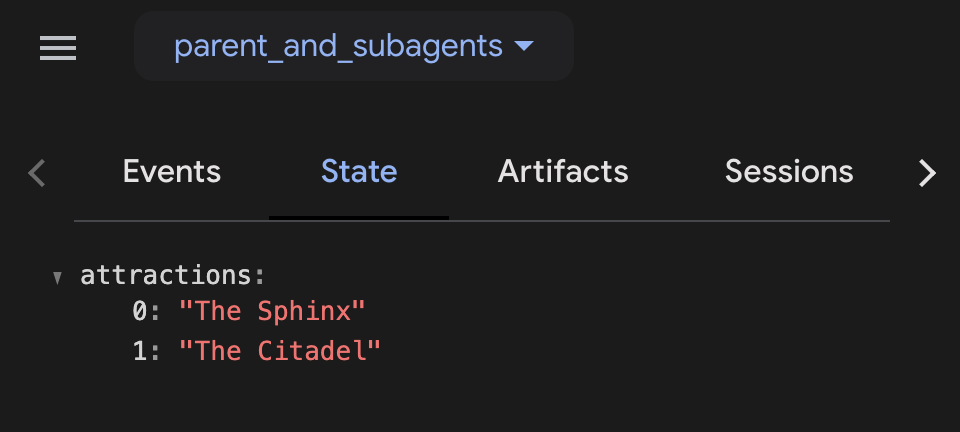
レスポンス ツールボックスをクリックして(チェックを入れます)、ツールの応答から作成されたイベントを確認します。actions フィールドに、状態の変化を示す state_delta が含まれているはずです。
エージェントから他にも観光スポットを選ぶよう促されるので、選択肢のいずれかを名前で指定してエージェントに返信します。
左側のナビゲーション メニューで [X] をクリックして、先ほど確認したイベントのフォーカスを解除します。
サイドバーに、イベントのリストとタブがいくつか表示されます。[State] タブを選択します。これは現在の状態を確認できるタブで、attractions 配列にはリクエストした 2 つの値が含まれています。
エージェントに次のメッセージを送ります。
instruction に従って、箇条書きリストの形でリストが返されます。
エージェントのテストが完了したら、ウェブブラウザのタブを閉じ、Cloud Shell ターミナルで Ctrl+C キーを押してサーバーを停止します。
このラボの後半では、状態を使用してエージェント間で通信する方法を説明します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
output_key パラメータを設定すると、出力全体がそのフィールド名で状態辞書に保存されます。
親エージェントからサブエージェントへの転送は、特定の分野に特化したサブエージェントが複数存在し、ユーザーにそれぞれとやり取りしてもらいたい場合には最適ですが、
ユーザーの順番を待たずにエージェントが次々と行動できるようにしたい場合は、ワークフロー エージェントを使用できます。たとえば、以下のようなシナリオでエージェントに任せたいタスクが決まっている場合は、ワークフロー エージェントを利用できます。
このようなタスクを遂行するために、ワークフロー エージェントにはサブエージェントがあり、各サブエージェントは動作することが保証されています。Agent Development Kit には 3 つの組み込みワークフロー エージェントが用意されており、独自のエージェントを定義することもできます。
SequentialAgentLoopAgentParallelAgentこのラボの残りの部分では、複数の LLM エージェント、ワークフロー エージェント、ツールを使用してエージェントのフローを制御するマルチエージェント システムを構築します。
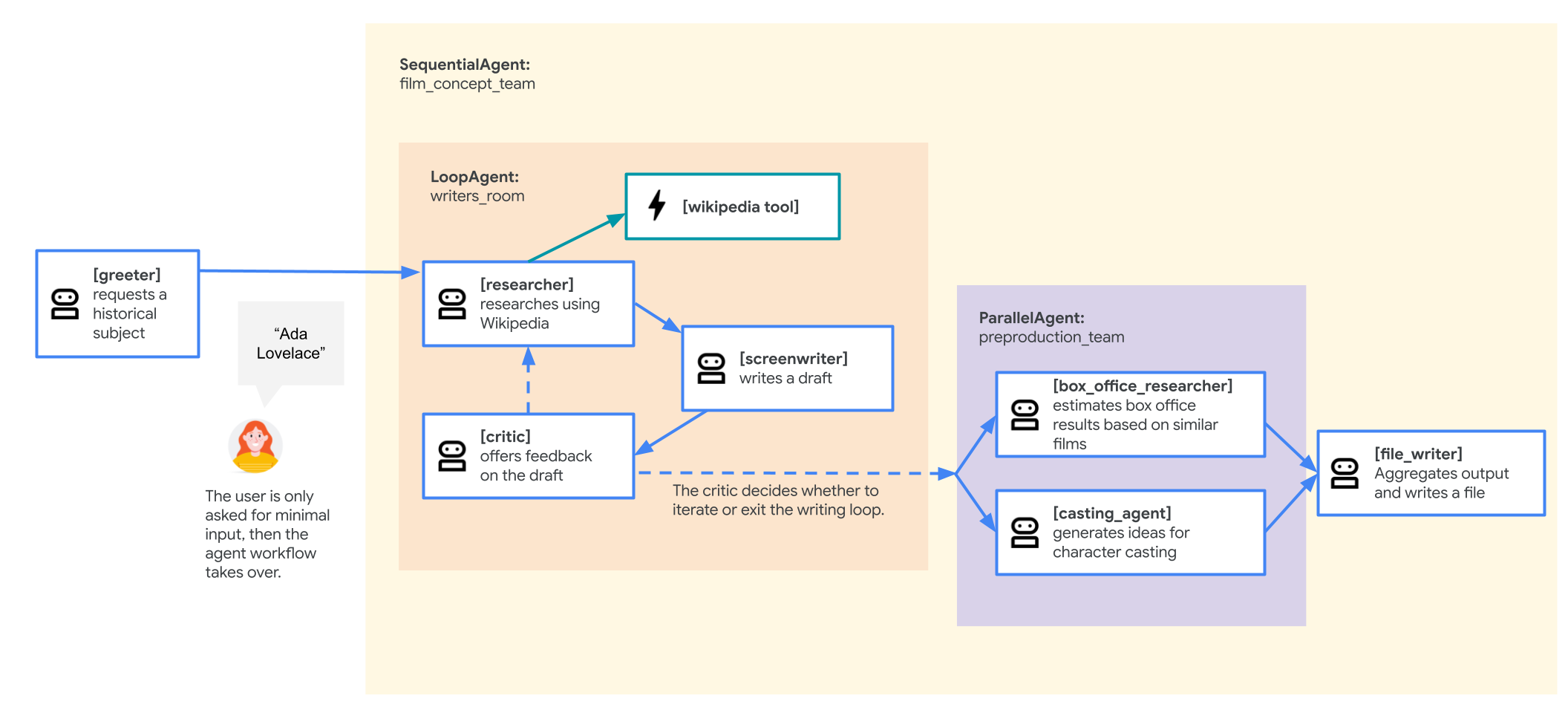
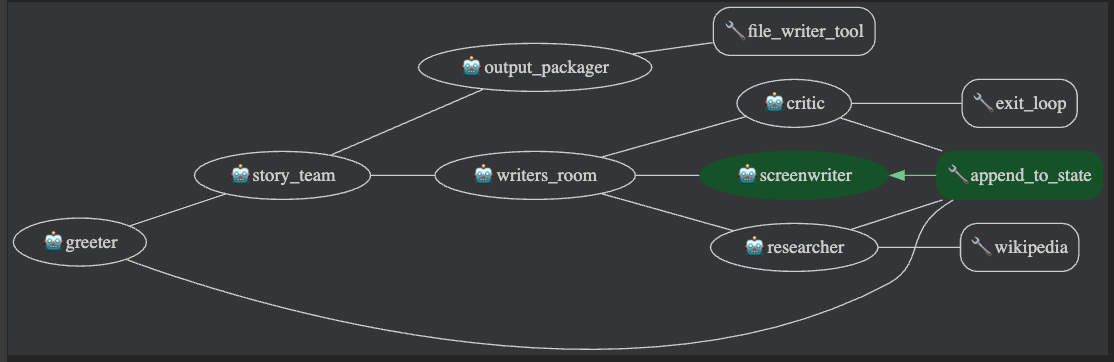
具体的には、歴史上の人物の生涯をモチーフにした新作の伝記映画の企画書を作成するエージェントを構築します。サブエージェントが調査を実施し、脚本家と批評家の間の反復的な執筆ループを処理し、最後に、別のサブエージェントがキャスティングのアイデアをブレインストーミングし、過去の興行収入データを使用して興行収入の結果を予測します。
マルチエージェント システムは最終的に次のようになります(画像をクリックすると拡大表示されます)。
まず、シンプルなバージョンから始めましょう。
SequentialAgent は、サブエージェントを線形シーケンスで実行します。sub_agents リスト内の各サブエージェントは、定義された順に 1 つずつ実行されます。
このエージェントは、特定の順序でタスクを実行する必要があり、あるタスクの出力が次のタスクの入力として使用されるワークフローに最適です。
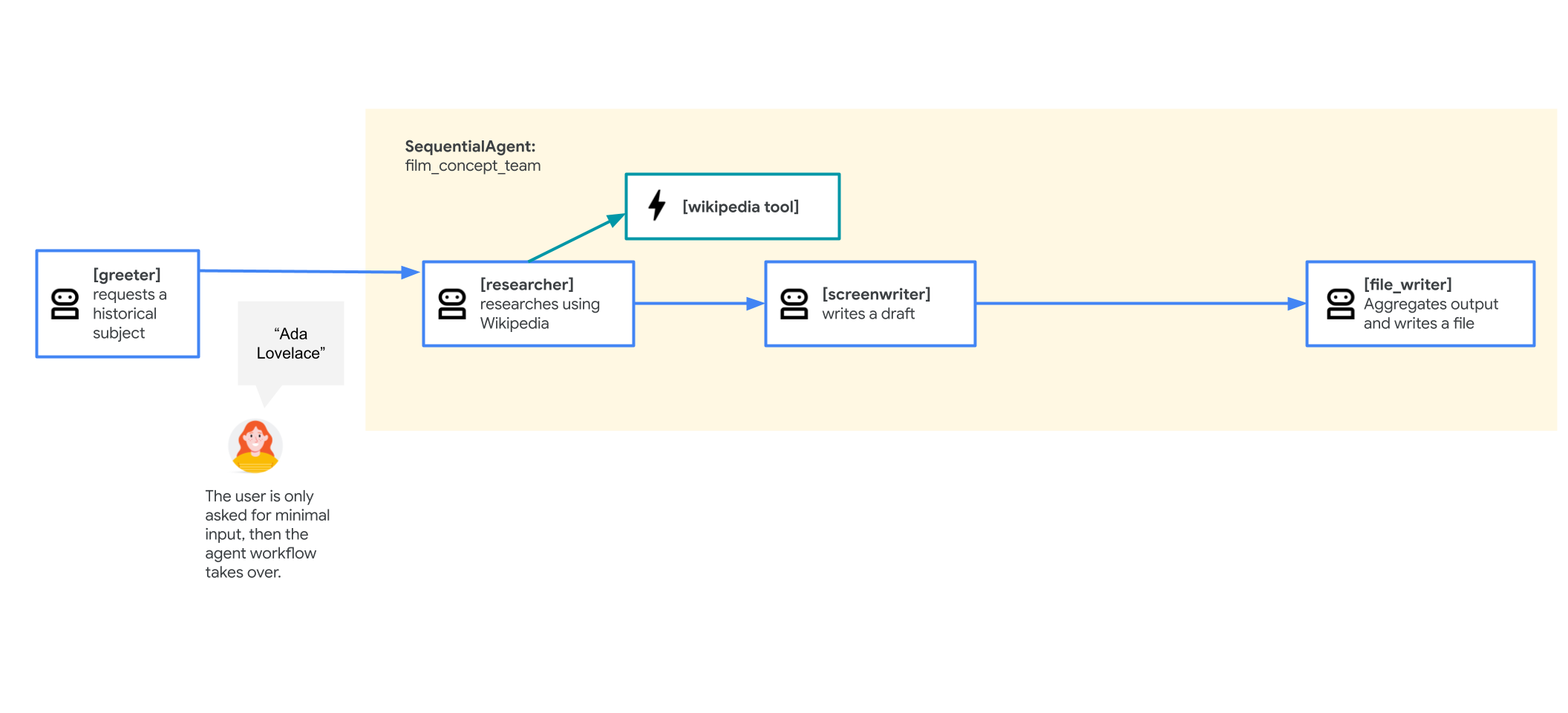
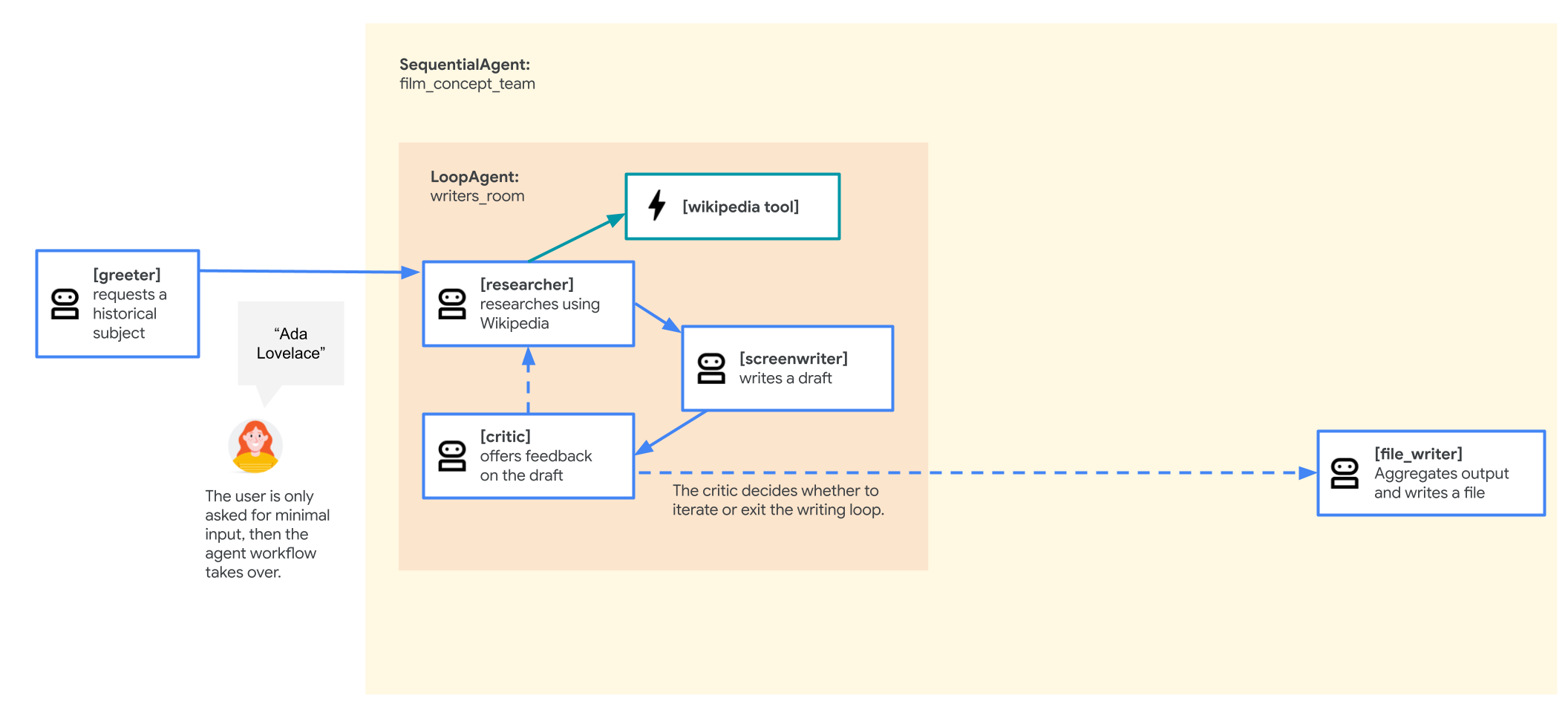
このタスクでは、SequentialAgent を実行して、映画の企画書作成マルチエージェント システムの最初のバージョンを構築します。エージェントの最初のドラフトは、次のような構造になります。
root_agent(greeter): ユーザーに挨拶してから、映画の主人公にする歴史上の人物をリクエストします
SequentialAgent は film_concept_team という名前で、次のサブエージェントで構成されています。
Cloud Shell エディタで、ディレクトリ adk_multiagent_systems/workflow_agents に移動します。
workflow_agents ディレクトリの agent.py ファイルをクリックします。
このエージェント定義ファイルに目を通してください。サブエージェントを先に定義してから親エージェントに割り当てる必要があるため、会話の流れに沿ってファイルを読み取るには、ファイルの下から上に向かってエージェントを読み取ります。
また、関数ツール append_to_state もあります。これは、エージェントがツールを使って状態の辞書値にコンテンツを追加できるようにする関数です。ツールを複数回呼び出す可能性があるエージェントや、LoopAgent を複数回パスして動作するエージェントにこの関数を使うと、エージェントが動作するたびに出力が保存されるため、特に便利です。
Cloud Shell ターミナルからウェブ インターフェースを起動して、エージェントの現在のバージョンを試してみます。--reload_agents 引数を含めて、エージェントの変更に基づいてエージェントがライブで再読み込みされるようにします。
adk web セッションをシャットダウンしていない場合、デフォルトのポート 8000 がブロックされますが、adk web --port 8001 などを使用して新しいポートで開発 UI を起動できます。
ウェブ インターフェースを新しいタブで表示するには、ターミナルの出力にある http://127.0.0.1:8000 リンクをクリックします。
新しいブラウザタブが開き、ADK 開発 UI が表示されます。
左側の [Select an agent] プルダウンから、[workflow_agents] を選択します。
「hello」と挨拶して会話を始めます。エージェントが応答するまでにしばらく時間がかかる場合があります。その後、映画のプロット生成を開始するために、歴史上の人物を入力するよう求められます。
歴史上の人物を入力するよう求められたら、任意の人物を入力するか、次の例を使用します。
Zhang Zhongjing(張仲景)- 紀元 2 世紀の有名な中国の医師。Ada Lovelace(エイダ ラブレス)- 初期のコンピュータに関する研究で知られるイギリスの数学者、作家Marcus Aurelius(マルクス・アウレリウス)- 哲学的な著作で知られるローマ皇帝。このワークフロー エージェントはワークフローを実行しながらエージェントを次々と呼び出し、~/adk_multiagent_systems/movie_pitches ディレクトリにプロット ファイルを書き込んでいきます。ファイルがディスクに書き込まれたら、ユーザーに知らせます。
ファイルが生成されたことを報告するメッセージが表示されない場合や、別の人物を試したい場合は、右上の [+ New Session] をクリックしてもう一度お試しください。
Cloud Shell エディタでエージェントの出力を確認します(横方向に何度もスクロールせずにテキスト全文を表示するには、Cloud Shell エディタのメニューで [View] > [Word Wrap] を選択して有効にすることをおすすめします)。
ADK 開発 UI で、会話のターンを表すエージェント アイコン(
イベントビューには、このセッションで使用されたエージェントとツールのツリーが視覚的に表示されます。プロット全体を表示するために、イベントパネルをスクロールしなければならない場合があります。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
LoopAgent は、定義されたシーケンスでサブエージェントを実行し、ユーザー入力を待つために動作を中断することなく、シーケンスの最初に戻って再び実行します。ループは、反復回数に達するか、サブエージェントの 1 つがループを終了する呼び出しを行うまで(通常は組み込みの exit_loop ツールを呼び出します)繰り返されます。
LoopAgent は、継続的な改良、モニタリング、または周期的なワークフローが必要なタスクを実行する場合に役立ちます。たとえば次のような場合です。
映画の企画書作成エージェントに LoopAgent を追加して、ストーリーの執筆中に調査と反復作業を複数回行えるようにしましょう。これにより台本が洗練されるだけでなく、ユーザーはより漠然とした入力から始められるようになります。たとえば、歴史上の人物を具体的に提案する代わりに、「古代の医者に関するストーリーが欲しい」とエージェントに伝えるだけで、調査と執筆の反復ループを通じて、適切な候補を見つけてストーリーを創り上げることができます。
修正されたエージェントは、次のように動作します。
SequentialAgent)は、次の要素で構成されています。
LoopAgent。以下の要素で構成されます。
SequentialAgent)にエスカレーションされて戻ってから、そのシーケンスの次のエージェントである file_writer に渡されます。このエージェントは前述と変わらず、映画のタイトルを付け、シーケンスの結果をファイルに書き込む役割を果たします。これらの変更を行うには:
adk_multiagent_systems/workflow_agents/agent.py ファイルで import 文を記述してツールを指定し、必要に応じてエージェントがループを終了できるようにします。
ループを終了するタイミングを判断するために critic を追加します。これは、プロットが完成したかどうかを判断するエージェントです。agent.py ファイルの # Agents セクション ヘッダーの下に、次の新しいエージェントを貼り付けます(既存のエージェントを上書きしないようにしてください)。ツールのひとつに exit_loop ツールが含まれていて、instructions にはその使い方に関する説明もあります。
writers_room という名前の新しい LoopAgent を作成します。このエージェントは、researcher、screenwriter、critic の反復ループを作成します。ループを通過するたびに、それまでの作業を批判的に検証し、次のラウンドに向けた改善点を導き出します。既存の film_concept_team(SequentialAgent)の上に次のコードを貼り付けます。
LoopAgent の作成コードに max_iterations パラメータが含まれていることに注意してください。これは、ループが終了するまでに実行される回数を定義します。別の方法を実装してループを中断する場合でも、反復の合計数に上限を課すことをおすすめします。
film_concept_team(SequentialAgent)を更新して、researcher と screenwriter を、先ほど作成した writers_room(LoopAgent)に置き換えます。file_writer エージェントは、シーケンスの最後にそのまま残します。film_concept_team は次のようになります。
ADK 開発 UI タブに戻り、右上の [+ New Session] ボタンをクリックして新しいセッションを開始します。
「hello」と挨拶して新しい会話を始めます。
歴史上の人物のタイプを選択するよう求められたら、関心のある人物を選んでください。次のような人物のイメージを伝えてみましょう。
an industrial designer who made products for the masses(大衆向け製品を制作した工業デザイナー)a cartographer (a map maker)(地図製作者)that guy who made crops yield more food(作物の増収に成功した男性)人物のタイプを選択したら、エージェントはループを反復してから、映画のタイトルを付け、筋書きをファイルに書き込みます。
Cloud Shell エディタを使用して、生成されたファイルを確認します。このファイルは adk_multiagent_systems/movie_pitches ディレクトリに保存されているはずです(ここでも、横方向に何度もスクロールせずにテキスト全文を表示するには、Cloud Shell エディタのメニューで [View] > [Word Wrap] を選択して有効にすることをおすすめします)。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ParallelAgent は、サブエージェントの同時実行を可能にします。各サブエージェントが独自のブランチで動作します。デフォルトでは、並列実行中のサブエージェントが会話履歴や状態を直接共有することはありません。
このエージェントは、タスクを同時処理できる独立したサブタスクに分担できる場合に有効です。このようなタスクに ParallelAgent を使用すると、全体的な実行時間を大幅に短縮できます。
このラボでは、新作映画に説得力を持たせるために、潜在的な興行収入に関する調査やキャスティングの初期案など、補足的なレポートを追加します。
修正されたエージェントは、次のように動作します。
SequentialAgent)は、次の要素で構成されています。
LoopAgent): 変更はなく、以下の要素で構成されています。
ParallelAgent)は、次の要素で構成されています。
この例のほとんどは、人間がチームで取り組むクリエイティブな作業になぞらえて定義されていますが、このワークフローは、複雑な一連のタスクを複数のサブエージェントに分担して、複雑な書類の下書きを生成する方法を示したものに過ぎず、人間のチームメンバーは下書きをさらに編集して改善することができます。
workflow_agents/agent.py ファイルの # Agents ヘッダーの下に、次の新しいエージェントと ParallelAgent を貼り付けます。
既存の film_concept_team エージェントの sub_agents リストを更新して、writers_room と file_writer の間に preproduction_team を含めます。
file_writer の instruction を次のように更新します。
ファイルを保存します。
ADK 開発 UI で、右上の [+ New Session] をクリックします。
「hello」と挨拶して会話を始めます。
プロンプトが表示されたら、興味のある別の登場人物のタイプを入力します。次のような人物のイメージを伝えてみましょう。
that actress who invented the technology for wifi(Wi-Fi の技術を発明した女優)an exciting chef(カリスマ性のあるシェフ)key players in the worlds fair exhibitions(万国博覧会の主要な出展者)エージェントが執筆とレポート生成を完了したら、adk_multiagent_systems/movie_pitches ディレクトリにあるファイルを確認します。プロセスのどこかで失敗した場合は、右上の [+ New Session] をクリックしてもう一度試してください。
SequentialAgent、LoopAgent、ParallelAgent の事前定義されたワークフロー エージェントでニーズを満たせない場合は、CustomAgent を使用して新しいワークフロー ロジックを柔軟に実装することができます。サブエージェント間のフロー制御、条件付き実行、状態管理についてパターンを定義できます。このエージェントは、複雑なワークフローやステートフルなオーケストレーションに加えて、カスタム ビジネスロジックをフレームワークのオーケストレーション レイヤに統合したい場合にも有用です。
このラボでは CustomAgent の作成は扱いませんが、必要になったときに思い出せるようにその存在を覚えておきましょう。
このラボでは、複数のエージェントを作成し、それらを親エージェントとサブエージェントの関係で関連付ける方法、セッションの状態に書き込み、エージェントへの指示で読み取る方法、ワークフロー エージェントを使用して、エージェント間で会話を直接受け渡す方法を学習しました。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2026 年 2 月 3 日
ラボの最終テスト日: 2026 年 2 月 3 日
Copyright 2026 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください
ラボを開始するには、この簡単な手順を完了してください。