Este conteúdo ainda não foi otimizado para dispositivos móveis.
Para aproveitar a melhor experiência, acesse nosso site em um computador desktop usando o link enviado a você por e-mail.
Visão geral
O BigQuery é compatível com vários tipos de instruções SQL, incluindo linguagem de definição de dados (DDL, na sigla em inglês), linguagem de manipulação de dados (DML, na sigla em inglês), funções definidas pelo usuário (UDFs, na sigla em inglês) e procedimentos armazenados.
O objetivo deste laboratório é fornecer aos profissionais da Snowflake o conhecimento e as habilidades necessárias para começar a trabalhar com SQL no BigQuery. Após concluir o laboratório, os profissionais da Snowflake vão entender melhor como usar SQL no BigQuery para criar, atualizar e trabalhar com estruturas de dados no BigQuery.
Neste laboratório, você vai criar tabelas e visualizações usando instruções DDL, atualizar tabelas usando instruções DML, mesclar dados usando SQL e personalizar funções definidas pelo usuário (UDFs) e procedimentos armazenados.
criar novas tabelas e visualizações usando instruções DDL;
atualizar dados de tabelas usando instruções DML;
mesclar dados e definir expressões de tabela comuns (CTEs, na sigla em inglês) usando instruções SQL SELECT;
personalizar UDFs e procedimentos armazenados.
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período sem custo financeiro.
Faça login no Google Skills usando uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta e copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Como começar o laboratório e fazer login no console
Clique no botão Começar o laboratório. Se for preciso pagar pelo laboratório, você verá um pop-up para selecionar a forma de pagamento.
Um painel aparece à esquerda contendo as credenciais temporárias que você precisa usar no laboratório.
Copie o nome de usuário e clique em Abrir console do Google.
O laboratório ativa os recursos e depois abre a página Escolha uma conta em outra guia.
Observação: abra as guias em janelas separadas, lado a lado.
Na página "Escolha uma conta", clique em Usar outra conta. A página de login abre.
Cole o nome de usuário que foi copiado do painel "Detalhes da conexão". Em seguida, copie e cole a senha.
Observação: é necessário usar as credenciais do painel "Detalhes da conexão". Não use suas credenciais do Google Skills. Caso tenha sua própria conta do Google Cloud, não a use para este laboratório (isso evita cobranças).
Acesse as próximas páginas:
Aceite os Termos e Condições.
Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
Não se inscreva em testes sem custo financeiro.
Depois de alguns instantes, o console do Cloud abre nesta guia.
Observação: para acessar a lista dos produtos e serviços do Google Cloud, clique no Menu de navegação no canto superior esquerdo.
Tarefa 1: criar conjuntos de dados e tabelas do BigQuery usando instruções DDL
No BigQuery, você pode usar a linguagem de definição de dados (DDL, na sigla em inglês) para criar conjuntos de dados e tabelas. Você também pode usar a instrução SQL LOAD DATA para carregar dados de um ou mais arquivos em uma tabela nova ou existente.
Nesta tarefa, você vai usar DDL para criar conjuntos de dados e tabelas no BigQuery e, em seguida, carregar dados nas tabelas novas com a instrução LOAD DATA.
No console do Google Cloud, no Menu de navegação (), em "Analytics", clique em BigQuery.
A caixa de mensagem "Olá! Este é o BigQuery no console do Cloud" vai aparecer. Essa caixa de mensagem inclui um link para o guia de início rápido e para as notas da versão.
Clique em Concluído.
Na barra do espaço de trabalho SQL, clique no ícone Consulta sem título para abrir o editor de código SQL.
No editor de consultas, copie e cole a consulta abaixo, depois clique em Executar:
CREATE SCHEMA IF NOT EXISTS
animals_dataset OPTIONS(
location="us");
Essa consulta cria um novo conjunto de dados do BigQuery chamado animals_dataset. Observe que a instrução DDL usa o termo SCHEMA para se referir a uma coleção lógica de tabelas, visualizações e outros recursos. No BigQuery, essa coleção é conhecida como "conjunto de dados".
No editor, execute as consultas abaixo para criar duas tabelas:
CREATE TABLE animals_dataset.owners(
OwnerID INT64 NOT NULL,
Name STRING);
CREATE TABLE animals_dataset.pets(
PetID INT64 NOT NULL,
OwnerID INT64 NOT NULL,
Type STRING,
Name STRING,
Weight FLOAT64);
Essas consultas criam duas tabelas chamadas tutores e animais de estimação no conjunto de dados do BigQuery que você criou anteriormente chamado animals_dataset.
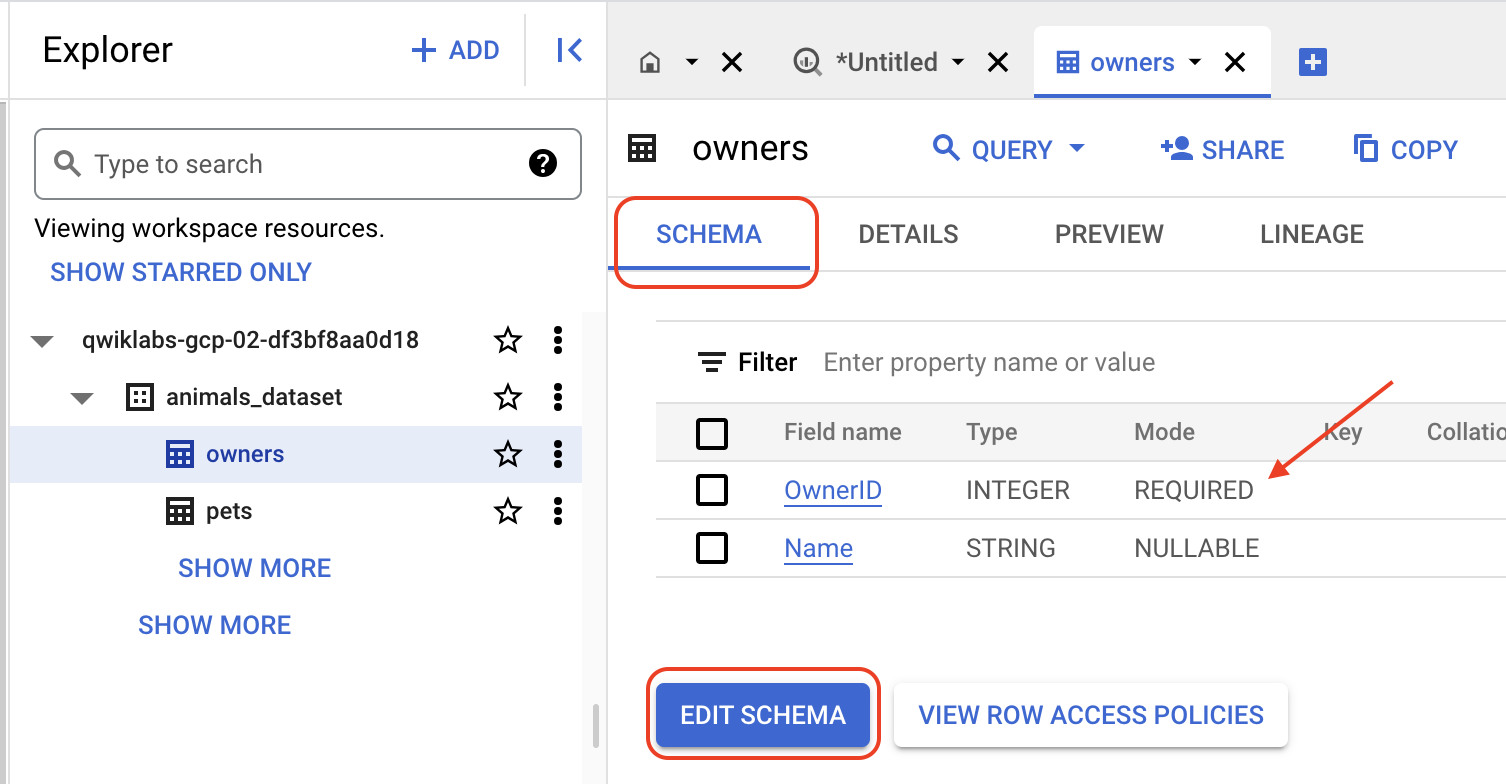
Antes de passar para a próxima etapa, atualize o modo do campo de REQUIRED para NULLABLE no esquema da tabela para evitar erros na etapa 5.
No painel Análises, selecione o nome da tabela, escolha a guia ESQUEMA, clique em EDITAR ESQUEMA e atualize o modo do campo de REQUIRED para NULLABLE. Repita essa etapa para todos os campos com o modo "REQUIRED" nas duas tabelas.
No editor de consultas, execute estas consultas:
LOAD DATA INTO animals_dataset.owners
FROM FILES (
skip_leading_rows=1,
format = 'CSV',
field_delimiter = ',',
uris = ['gs://tcd_repo/data/environmental/animals/owners.csv']);
LOAD DATA INTO animals_dataset.pets
FROM FILES (
skip_leading_rows=1,
format = 'CSV',
field_delimiter = ',',
uris = ['gs://tcd_repo/data/environmental/animals/pets.csv']);
Essas consultas carregam dados nas tabelas tutores e animais de estimação usando arquivos CSV no Cloud Storage.
O painel Resultados mostra uma mensagem indicando que a instrução LOAD foi executada com sucesso.
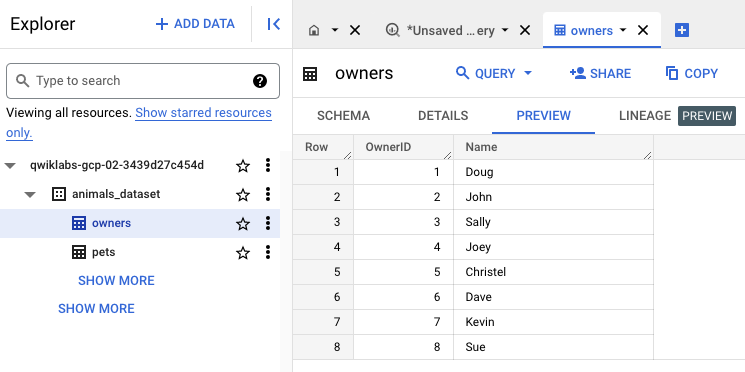
Expanda o painel "Análise" (painel lateral esquerdo) que lista o conjunto de dados e a tabela. Depois, clique no nome da tabela tutores.
Clique nas guias Detalhes e Visualização para ver mais informações sobre a tabela e uma prévia dos dados.
Clique em Atualizar (canto superior direito) para atualizar os dados na guia Visualização.
Repita as etapas 6 e 7 para ver mais informações sobre a tabela animais de estimação e uma prévia dos dados.
Clique em Verificar meu progresso para conferir o objetivo.
Criar conjunto de dados e tabelas do BigQuery
Tarefa 2: atualizar os dados das tabelas do BigQuery usando instruções DML
No BigQuery, você pode usar a DML para atualizar os dados em uma tabela existente, incluindo para adicionar, alterar e excluir dados das tabelas do BigQuery.
Depois de cada inserção, o painel Resultados mostra que um registro foi adicionado à tabela animais de estimação.
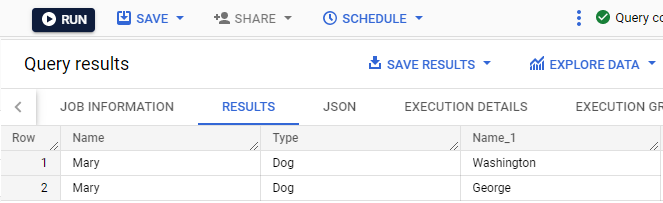
No editor de consultas, execute a consulta abaixo para verificar se Mary e os dois cachorros dela estão nas tabelas apropriadas:
SELECT o.Name, p.Type, p.Name
FROM
animals_dataset.owners o
JOIN
animals_dataset.pets p
ON
o.OwnerID = p.OwnerID
WHERE
o.Name = 'Mary';
O registro de Mary na tabela tutores foi unido aos dois registros na tabela animais de estimação dos cachorros dela: George e Washington.
No editor de consultas, execute a consulta abaixo para atualizar todos os valores do tipo de animal "Cachorro" para "Cão":
UPDATE
animals_dataset.pets
SET
Type = 'Canine'
WHERE
Type = 'Dog';
Essa instrução modifica dez linhas na tabela animais de estimação.
Clique em Acessar tabela e depois na guia "Visualização".
Verifique se todos os cachorros agora são classificados como cães na tabela animais de estimação.
Clique em Atualizar (canto superior direito) para atualizar os dados na guia Visualização.
No editor de consultas, execute a consulta abaixo para excluir todos os valores do tipo de animal "Sapo":
DELETE FROM
animals_dataset.pets
WHERE
Type = 'Frog';
Essa instrução remove uma linha da tabela animais de estimação.
Clique em Acessar tabela e depois na guia Visualização.
Verifique se todos os sapos foram removidos da tabela animais de estimação.
Clique em Atualizar (canto superior direito) para atualizar os dados na guia Visualização.
Clique em Verificar meu progresso para conferir o objetivo.
Atualizar os dados da tabela do BigQuery usando instruções DML
Tarefa 3: mesclar dados e escrever CTEs usando as instruções SQL SELECT
No BigQuery, você pode escrever instruções SQL SELECT com sintaxe para mesclagens, CTEs, ordenação, agrupamento, filtros, mudanças de estilo do conteúdo, janelamento e muito mais para recuperar os dados necessários.
Para saber mais sobre a sintaxe SQL SELECT e como trabalhar com dados em tabelas do BigQuery, consulte a documentação Sintaxe das consultas.
Nesta tarefa, você vai escrever instruções SQL SELECT que incluem operações JOIN para mesclar várias tabelas e cláusulas WITH para definir CTEs.
No editor de consultas, execute a consulta abaixo com um JOIN para selecionar todos os tutores e seus animais de estimação:
SELECT
o.Name, p.Type, p.Name, p.Weight
FROM
animals_dataset.owners o
JOIN
animals_dataset.pets p
ON
o.OwnerID = p.OwnerID;
No editor de consultas, execute a mesma consulta com uma cláusula WHERE para selecionar apenas os cães:
SELECT
o.Name, p.Type, p.Name, p.Weight
FROM
animals_dataset.owners o
JOIN
animals_dataset.pets p
ON
o.OwnerID = p.OwnerID
WHERE
p.Type = "Canine";
No editor de consultas, execute a mesma consulta com um ORDER BY para classificar os resultados por nome do tutor.
SELECT
o.Name, p.Type, p.Name, p.Weight
FROM
animals_dataset.owners o
JOIN
animals_dataset.pets p
ON
o.OwnerID = p.OwnerID
WHERE
p.Type = "Canine"
ORDER BY
o.Name ASC;
No editor de consultas, execute a consulta abaixo para contar os animais de estimação por tipo:
SELECT
type, COUNT(*) AS count
FROM
animals_dataset.pets
GROUP BY
type
ORDER BY
count DESC;
A tabela animais de estimação tem 10 cães, 5 gatos, 2 porcos e 2 tartarugas.
No editor de consultas, execute a consulta abaixo para contar os animais de estimação por tutor.
SELECT
o.Name, COUNT(p.Name) AS count
FROM
animals_dataset.owners o
JOIN
animals_dataset.pets p
ON
o.OwnerID = p.OwnerID
GROUP BY
o.Name
ORDER BY
count DESC;
O tutor chamado Doug tem o maior número de animais de estimação, que totaliza 4.
No editor de consultas, execute a consulta abaixo para retornar as informações dos animais de estimação como um campo aninhado e repetido:
SELECT
o.OwnerID,
o.Name AS OwnerName,
ARRAY_AGG(STRUCT(
p.Name AS PetName,
p.Type,
p.Weight)) AS Pets
FROM
animals_dataset.owners AS o
JOIN
animals_dataset.pets AS p
ON
o.OwnerID = p.OwnerID
GROUP BY
o.OwnerID, o.Name;
Observação :
No BigQuery, campos aninhados e repetidos são armazenados como ARRAYs de STRUCTs. A sintaxe ARRAY_AGG(STRUCT…) fornece os resultados como valores aninhados e repetidos, facilitando a visualização das relações entre os dados porque os valores unidos são organizados de forma clara.
Outra alternativa de SQL no BigQuery é usar uma cláusula WITH para definir CTEs e ver os resultados de outra consulta. Com essa sintaxe, você evita usar instruções SQL aninhadas, facilitando a leitura do código.
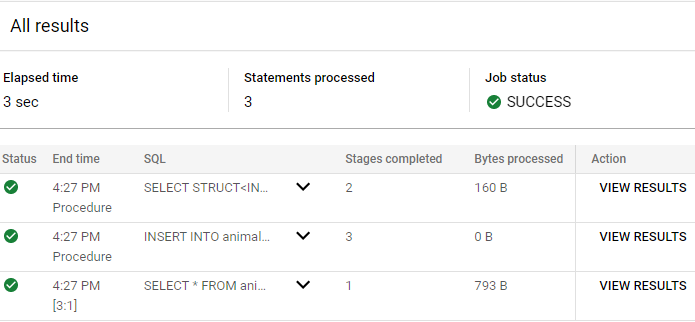
No editor de consultas, execute a consulta abaixo para definir uma CTE com base na anterior:
WITH owners_pets AS (SELECT
o.OwnerID,
o.Name AS OwnerName,
ARRAY_AGG(STRUCT(
p.Name AS PetName,
p.Type,
p.Weight)) AS Pets
FROM
animals_dataset.owners AS o
JOIN
animals_dataset.pets AS p
ON
o.OwnerID = p.OwnerID
GROUP BY
o.OwnerID, o.Name)
SELECT
op.OwnerName, op.Pets
FROM
owners_pets AS op;
Clique em Verificar meu progresso para conferir o objetivo.
Mesclar dados e escrever CTEs usando instruções SQL SELECT
Tarefa 4: criar tabelas e prévias usando instruções DDL
Em uma tarefa anterior, você usou DDL para criar conjuntos de dados e tabelas do BigQuery. No BigQuery, você também pode usar DDL para criar prévias lógicas e materializadas.
Para saber mais sobre como usar instruções DDL para criar visualizações no BigQuery, consulte a documentação Introdução às visualizações.
Nesta tarefa, você vai usar DDL para criar tabelas, visualizações lógicas e visualizações materializadas.
No editor de consultas, execute o código abaixo para gravar os resultados de uma consulta em uma nova tabela:
CREATE OR REPLACE TABLE
animals_dataset.owners_pets AS (
SELECT
o.OwnerID,
o.Name AS OwnerName,
ARRAY_AGG(STRUCT(
p.PetID,
p.Name AS PetName,
p.Type,
p.Weight)) AS Pets
FROM
animals_dataset.owners AS o
JOIN
animals_dataset.pets AS p
ON
o.OwnerID = p.OwnerID
GROUP BY
o.OwnerID, o.Name
);
Expanda o painel "Análise" (painel esquerdo) que lista o conjunto de dados e a tabela. Depois, clique no nome da tabela owner_pets.
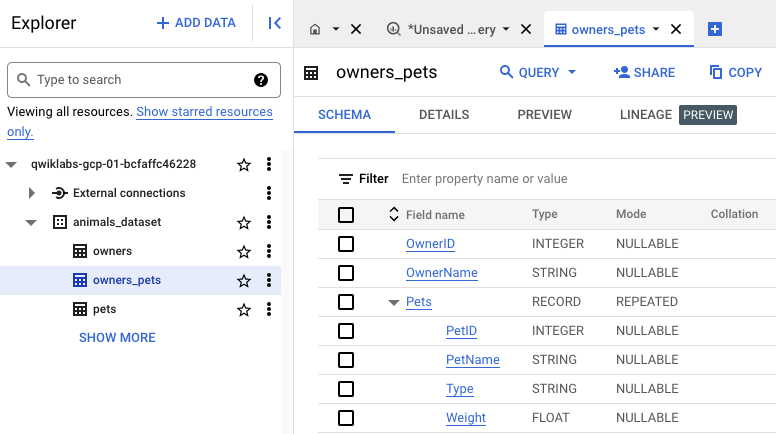
Clique na guia Esquema para revisar o esquema da tabela chamada owners_pets.
O esquema inclui um campo aninhado e repetido chamado Animais de estimação, com o ID, o nome, o tipo e o peso de cada animal de estimação para cada tutor.
Em uma tarefa anterior, você executou uma consulta que uniu as tabelas tutores e animais de estimação para contar o número de animais de estimação de cada tutor. Agora que os dados estão em um campo aninhado e repetido, você pode usar a função ARRAY_LENGTH para ver o número de animais de estimação de cada tutor.
No editor de consultas, execute a consulta abaixo para retornar o número de animais de estimação de cada tutor:
SELECT
OwnerName,
ARRAY_LENGTH(Pets) AS count
FROM
animals_dataset.owners_pets
ORDER BY
count DESC;
No editor de consultas, execute a consulta abaixo para criar uma visualização lógica que retorne apenas animais de estimação pequenos (com até 9 kg):
CREATE OR REPLACE VIEW
animals_dataset.small_pets AS (
SELECT
*
FROM
animals_dataset.pets
WHERE
weight <= 20
);
Clique em Acessar visualização.
No painel "Análise", clique em Ver ações (ícone com três botões verticais) na visualização small_pets e selecione Consulta.
No editor de consultas, execute a consulta abaixo para analisar os dados na visualização:
SELECT
PetID, Weight
FROM
animals_dataset.small_pets;
No BigQuery, as visualizações materializadas são pré-calculadas e armazenam os resultados de uma consulta em cache periodicamente para aumentar o desempenho e a eficiência. As visualizações materializadas podem ajudar muito em consultas que exigem processamento complexo, como agregações.
No editor de consultas, execute a consulta abaixo para criar uma visualização materializada que retorne o peso total de cada tipo de animal de estimação:
CREATE OR REPLACE MATERIALIZED VIEW
animals_dataset.pet_weight_by_type AS (
SELECT
type,
SUM(Weight) AS total_weight
FROM
animals_dataset.pets
GROUP BY
type
);
Clique em Acessar visualização materializada.
No painel "Análise", clique em Ver ações (ícone com três botões verticais) na visualização materializada pet_weight_by_type e selecione "Consulta".
No editor de consultas, execute a consulta abaixo para analisar os dados na visualização materializada:
SELECT
type, total_weight
FROM
animals_dataset.pet_weight_by_type;
Os cães têm o maior peso total, totalizando 142 kg.
Clique em Verificar meu progresso para conferir o objetivo.
Criar tabelas e visualizações usando instruções DDL
Tarefa 5: personalizar UDFs e procedimentos armazenados
No BigQuery, é possível personalizar uma UDF quando não houver uma função integrada que já faça o que você precisa. Uma UDF aceita uma ou mais colunas de entrada, executa ações na entrada e retorna o resultado dessas ações como saída. Além disso, você também pode personalizar procedimentos armazenados como funções que executam coleções de instruções SQL, como SELECT, INSERT e outras, na ordem desejada.
Nesta tarefa, você vai definir UDFs e procedimentos armazenados para recalcular valores atuais em uma tabela e facilitar a adição de novos registros de dados a uma tabela.
No editor de consultas, execute o código abaixo para criar uma UDF que converte libras em quilogramas:
CREATE OR REPLACE FUNCTION animals_dataset.PoundsToKilos(pounds FLOAT64)
AS (
round(pounds / 2.2, 1)
);
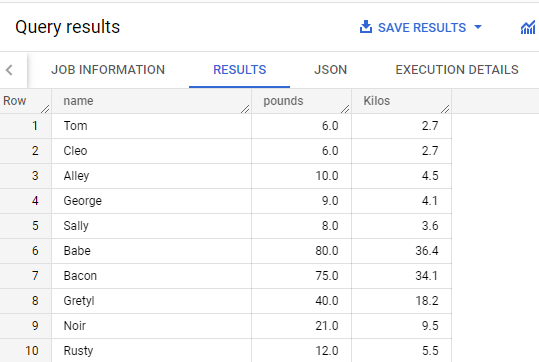
No editor de consultas, execute esta consulta para testar a UDF:
SELECT
name,
weight AS pounds,
animals_dataset.PoundsToKilos(Weight) AS Kilos
FROM
animals_dataset.pets;
Você também pode criar um procedimento armazenado para facilitar a adição de um novo animal de estimação. O procedimento abaixo encontra o maior ID de animal de estimação na tabela animais e adiciona o valor 1 a esse ID. Em seguida, ele atribui esse novo valor como o ID do novo animal de estimação e retorna o valor do novo ID quando o animal de estimação é adicionado.
No editor de consultas, execute a consulta abaixo para criar um procedimento armazenado de inclusão de um novo animal de estimação:
CREATE OR REPLACE PROCEDURE animals_dataset.create_pet(
customerID INT64, type STRING, name STRING, weight FLOAT64, out newPetID INT64)
BEGIN
SET newPetID = (SELECT MAX(PetID) + 1 FROM animals_dataset.pets);
INSERT INTO animals_dataset.pets (PetID, OwnerID, Type, Name, Weight)
VALUES(newPetID, customerID, type, name, weight);
END
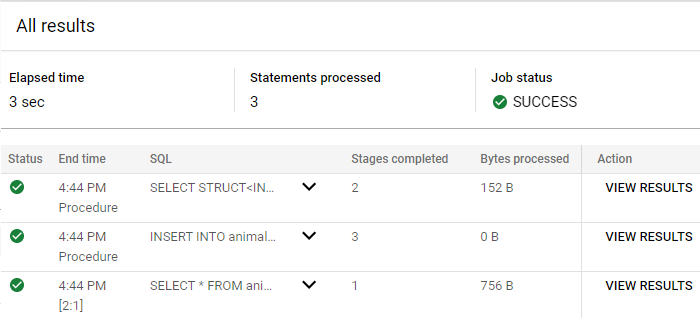
No editor de consultas, execute a consulta abaixo para testar o procedimento armazenado:
DECLARE newPetID INT64;
CALL animals_dataset.create_pet(1, 'Dog', 'Duke', 15.0, newPetID);
SELECT *
FROM
animals_dataset.pets
WHERE
PetID = newPetID;
Clique em Ver resultados para a última instrução SELECT *.
Observe que a variável de saída da função é o registro recém-criado de um cachorro chamado Duke com um ID de animal de estimação igual a 30.
No editor de consultas, execute a consulta abaixo para adicionar outro animal de estimação:
DECLARE newPetID INT64;
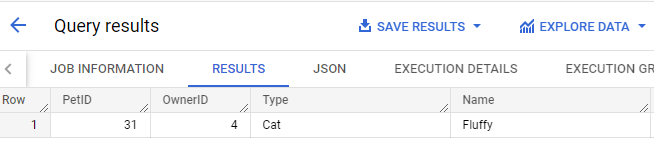
CALL animals_dataset.create_pet(4, 'Cat', 'Fluffy', 6.0, newPetID);
SELECT *
FROM
animals_dataset.pets
WHERE
PetID = newPetID;
Clique em Ver resultados para a última instrução SELECT *.
Observe que o valor do campo "ID" continua aumentando. O novo ID do gato Fluffy é 31.
No editor de consultas, execute a consulta abaixo para verificar se os dois novos animais de estimação foram adicionados à tabela animais:
SELECT *
FROM
animals_dataset.pets
WHERE
Name in ('Duke', 'Fluffy');
Clique em Verificar meu progresso para conferir o objetivo.
Personalizar UDFs e procedimentos armazenados
Finalize o laboratório
Após concluir o laboratório, clique em Terminar o laboratório. O Google Skills remove os recursos usados e limpa a conta para você.
Você poderá classificar sua experiência neste laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
A melhor maneira de executar este laboratório é usando uma janela de navegação anônima
ou privada. Isso evita conflitos entre sua conta pessoal
e a conta de estudante, o que poderia causar cobranças extras
na sua conta pessoal.
Neste laboratório, você vai criar tabelas e visualizações usando instruções DDL, atualizar tabelas usando instruções DML, mesclar dados usando SQL e personalizar funções definidas pelo usuário (UDFs) e procedimentos armazenados.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 90 minutos
·
Tempo para conclusão: 60 minutos




 ), em "Analytics", clique em BigQuery.
), em "Analytics", clique em BigQuery.