Instructions et exigences de configuration de l'atelier
Protégez votre compte et votre progression. Utilisez toujours une fenêtre de navigation privée et les identifiants de l'atelier pour exécuter cet atelier.
Utiliser SQL dans BigQuery pour les utilisateurs professionnels de Snowflake
Ce contenu n'est pas encore optimisé pour les appareils mobiles.
Pour une expérience optimale, veuillez accéder à notre site sur un ordinateur de bureau en utilisant un lien envoyé par e-mail.
Présentation
BigQuery est compatible avec de nombreux types d'instructions SQL, y compris le langage de définition de données (LDD), le langage de manipulation de données (LMD), les fonctions définies par l'utilisateur (UDF) et les procédures stockées.
L'objectif de cet atelier est de fournir aux professionnels de Snowflake les connaissances et les compétences nécessaires pour commencer à utiliser SQL dans BigQuery. À la fin de cet atelier, les utilisateurs professionnels de Snowflake comprendront mieux comment utiliser SQL dans BigQuery pour créer, mettre à jour et utiliser des structures de données dans BigQuery.
Dans cet atelier, vous allez créer des tables et des vues à l'aide d'instructions LDD, mettre à jour des tables à l'aide d'instructions LMD, joindre des données à l'aide de SQL, et définir des fonctions définies par l'utilisateur (UDF) et des procédures stockées personnalisées.
créer des tables et des vues à l'aide d'instructions LDD ;
actualiser les données existantes d'une table à l'aide d'instructions LMD ;
joindre des données et définir des expressions de table courantes (CTE, Common Table Expressions) à l'aide d'instructions SQL SELECT ;
paramétrer des UDF et des procédures stockées personnalisées.
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Google Skills dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pourrez pas le mettre sur pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à la console Google Cloud.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront facturés.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Démarrer votre atelier et vous connecter à la console
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous verrez un panneau contenant les identifiants temporaires à utiliser pour cet atelier.
Copiez le nom d'utilisateur, puis cliquez sur Ouvrir la console Google.
L'atelier lance les ressources, puis la page Sélectionner un compte dans un nouvel onglet.
Remarque : Ouvrez les onglets dans des fenêtres distinctes, placées côte à côte.
Sur la page "Sélectionner un compte", cliquez sur Utiliser un autre compte. La page de connexion s'affiche.
Collez le nom d'utilisateur que vous avez copié dans le panneau "Détails de connexion". Copiez et collez ensuite le mot de passe.
Remarque : Vous devez utiliser les identifiants fournis dans le panneau "Détails de connexion", et non ceux de votre compte Google Skills. Si vous possédez un compte Google Cloud, ne vous en servez pas pour cet atelier (vous éviterez ainsi que des frais vous soient facturés).
Accédez aux pages suivantes :
Acceptez les conditions d'utilisation.
N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
Ne vous inscrivez pas aux essais sans frais.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Vous pouvez afficher le menu qui contient la liste des produits et services Google Cloud en cliquant sur le menu de navigation en haut à gauche.
Tâche 1 : Créer un ensemble de données et des tables BigQuery à l'aide d'instructions LDD
Dans BigQuery, vous pouvez utiliser le langage de définition de données (LDD) pour créer des ensembles de données et des tables. L'instruction SQL LOAD DATA vous permet quant à elle de charger les données d'un ou de plusieurs fichiers dans une table nouvelle ou existante.
Pour en savoir plus sur l'utilisation des instructions LDD pour créer des ensembles de données et des tables BigQuery, ainsi que sur l'utilisation de l'instruction SQL LOAD DATA pour charger des données, consultez la documentation sur les instructions CREATE SCHEMA, CREATE TABLE et LOAD DATA.
Dans cette tâche, vous allez utiliser des instructions LDD pour créer un ensemble de données et des tables dans BigQuery, puis vous allez charger des données dans ces nouvelles tables à l'aide de l'instruction LOAD DATA.
Dans la console Google Cloud, accédez au menu de navigation (), puis sous "Analyse", cliquez sur BigQuery.
Le message "Bienvenue sur BigQuery dans la console Cloud" s'affiche. Il contient un lien vers le guide de démarrage rapide et les notes de version.
Cliquez sur OK.
Dans la barre d'outils de l'espace de travail SQL, cliquez sur l'icône Requête sans titre pour ouvrir l'éditeur de code SQL.
Copiez la requête suivante et collez-la dans l'éditeur de requête, puis cliquez sur Exécuter :
CREATE SCHEMA IF NOT EXISTS
animals_dataset OPTIONS(
location="us");
Cette requête crée un ensemble de données BigQuery nommé animals_dataset. Notez que l'instruction LDD utilise le terme "SCHEMA" pour désigner une collection logique de tables, de vues et d'autres ressources, ce qui correspond à un "ensemble de données" dans BigQuery.
Dans l'éditeur de requête, exécutez les requêtes suivantes pour créer deux tables :
CREATE TABLE animals_dataset.owners(
OwnerID INT64 NOT NULL,
Name STRING);
CREATE TABLE animals_dataset.pets(
PetID INT64 NOT NULL,
OwnerID INT64 NOT NULL,
Type STRING,
Name STRING,
Weight FLOAT64);
Ces requêtes créent deux tables appelées owners et pets dans l'ensemble de données BigQuery animals_dataset que vous avez créé précédemment.
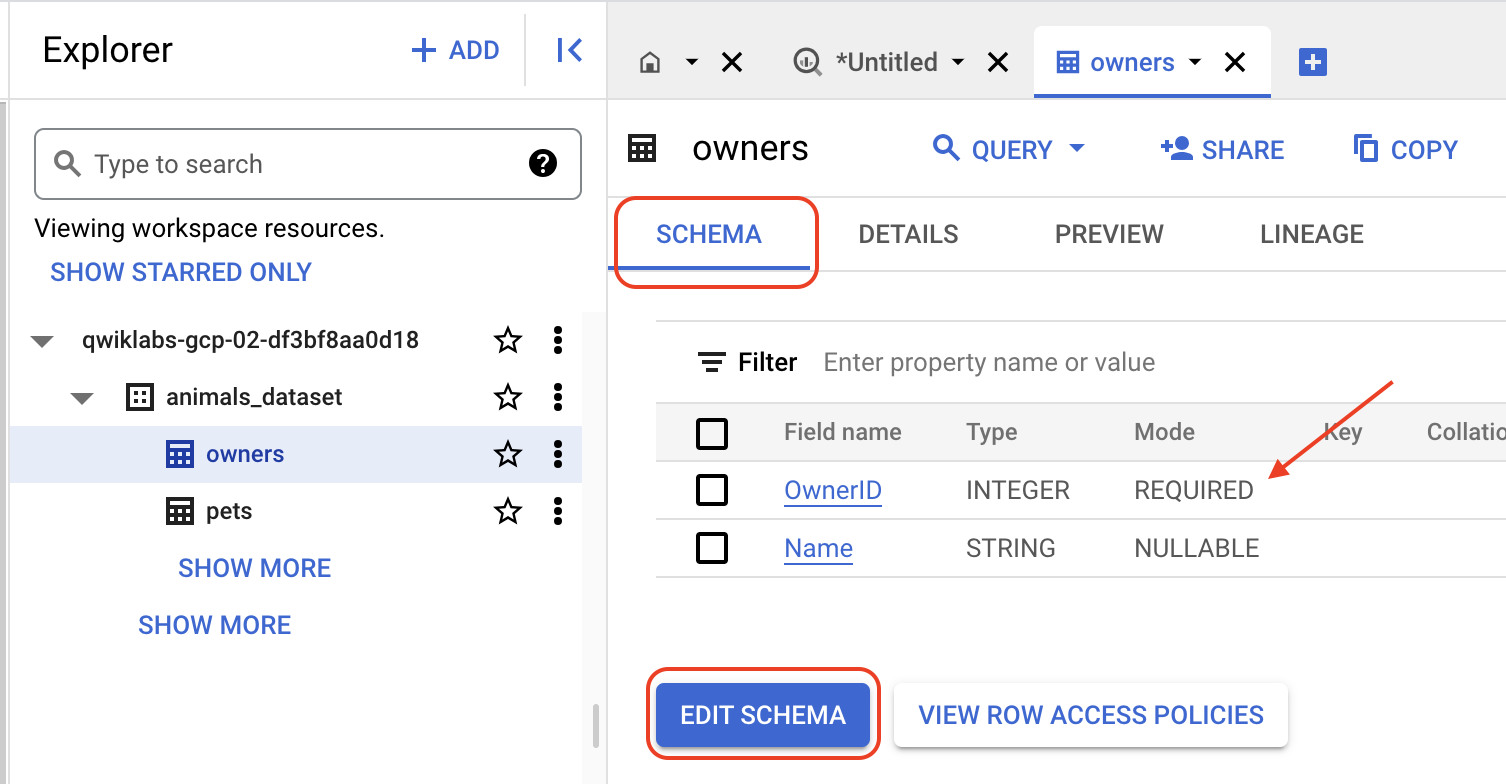
Avant de passer à l'étape suivante, mettez le champ en mode REQUIRED au lieu de NULLABLE dans le schéma de la table afin d'éviter les erreurs à l'étape 5.
Dans le panneau Explorateur, sélectionnez le nom de la table, choisissez l'onglet SCHÉMA, cliquez sur MODIFIER LE SCHÉMA, puis mettez le champ en mode REQUIRED au lieu de NULLABLE. Veuillez répéter cette étape pour tous les champs dont le mode est "REQUIRED" dans les deux tables.
Dans l'éditeur de requête, exécutez les requêtes suivantes :
LOAD DATA INTO animals_dataset.owners
FROM FILES (
skip_leading_rows=1,
format = 'CSV',
field_delimiter = ',',
uris = ['gs://tcd_repo/data/environmental/animals/owners.csv']);
LOAD DATA INTO animals_dataset.pets
FROM FILES (
skip_leading_rows=1,
format = 'CSV',
field_delimiter = ',',
uris = ['gs://tcd_repo/data/environmental/animals/pets.csv']);
Ces requêtes chargent les données dans les tables owners et pets à partir de fichiers CSV dans Cloud Storage.
Le volet Résultats affiche un message indiquant que l'instruction LOAD s'est exécutée correctement.
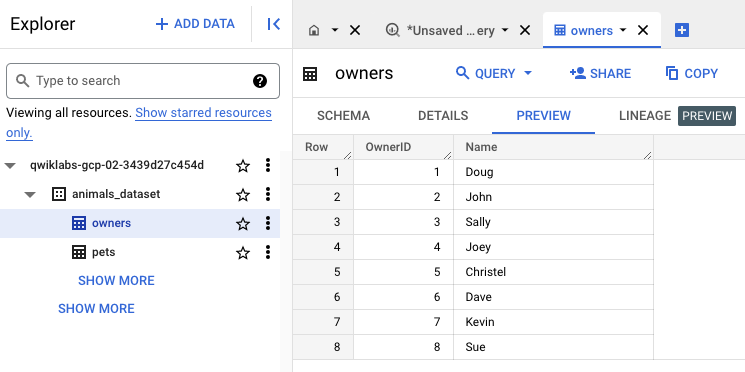
Développez le volet "Explorateur" (panneau de gauche) qui liste l'ensemble de données et la table, puis cliquez sur le nom de la table owners.
Cliquez sur les onglets Détails et Aperçu pour afficher plus d'informations sur la table ainsi qu'un aperçu des données.
Vous pouvez cliquer sur Actualiser (en haut à droite) pour mettre à jour les données dans l'onglet Aperçu.
Répétez les étapes 6 et 7 pour afficher plus d'informations sur la table nommée pets, ainsi qu'un aperçu des données.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer un ensemble de données et des tables BigQuery
Tâche 2 : Actualiser les données d'une table BigQuery à l'aide d'instructions LMD
Dans BigQuery, vous pouvez utiliser des instructions LMD pour actualiser les données d'une table existante, y compris pour ajouter, modifier et supprimer des données dans vos tables BigQuery.
Après chaque requête d'insertion, le volet Résultats indique qu'un enregistrement a été ajouté à la table pets.
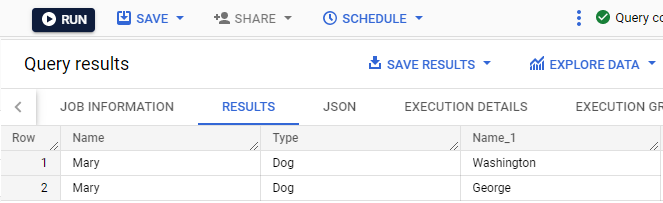
Dans l'éditeur de requête, exécutez la requête suivante pour vérifier que Mary et ses deux chiens ont été ajoutés aux tables appropriées :
SELECT o.Name, p.Type, p.Name
FROM
animals_dataset.owners o
JOIN
animals_dataset.pets p
ON
o.OwnerID = p.OwnerID
WHERE
o.Name = 'Mary';
L'enregistrement de Mary dans la table owners a été joint aux deux enregistrements de ses chiens, George et Washington, dans la table pets.
Dans l'éditeur de requête, exécutez la requête suivante pour remplacer toutes les valeurs du type d'animal "Dog" (Chien) par "Canine" (Canidé) :
UPDATE
animals_dataset.pets
SET
Type = 'Canine'
WHERE
Type = 'Dog';
Cette instruction modifie 10 lignes dans la table pets.
Cliquez sur Accéder à la table, puis sur l'onglet Aperçu.
Vérifiez que tous les chiens sont désormais identifiés comme canidés dans la table pets.
Vous pouvez cliquer sur Actualiser (en haut à droite) pour mettre à jour les données dans l'onglet Aperçu.
Dans l'éditeur de requête, exécutez la requête suivante pour supprimer toutes les valeurs du type d'animal "Frog" (Grenouille) :
DELETE FROM
animals_dataset.pets
WHERE
Type = 'Frog';
Cette instruction supprime une ligne de la table pets.
Cliquez sur Accéder à la table, puis sur l'onglet Aperçu.
Vérifiez que toutes les grenouilles ont été supprimées de la table pets.
Vous pouvez cliquer sur Actualiser (en haut à droite) pour mettre à jour les données dans l'onglet Aperçu.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Actualiser les données d'une table BigQuery à l'aide d'instructions LMD
Tâche 3 : Joindre des données et écrire des CTE à l'aide d'instructions SQL SELECT
Dans BigQuery, vous pouvez écrire des instructions SQL SELECT avec une syntaxe pour les jointures, les CTE, le tri, le regroupement, le filtrage, le croisement, le fenêtrage et plus encore, afin de récupérer les données dont vous avez besoin.
Pour en savoir plus sur la syntaxe SQL SELECT permettant d'utiliser les données dans des tables BigQuery, consultez la documentation Syntaxe des requêtes.
Dans cette tâche, vous allez écrire des instructions SQL SELECT qui incluent des opérations JOIN pour joindre plusieurs tables et des clauses WITH pour définir des CTE.
Dans l'éditeur de requête, exécutez la requête suivante avec une opération JOIN pour sélectionner tous les propriétaires et leurs animaux de compagnie :
SELECT
o.Name, p.Type, p.Name, p.Weight
FROM
animals_dataset.owners o
JOIN
animals_dataset.pets p
ON
o.OwnerID = p.OwnerID;
Dans l'éditeur de requête, exécutez la même requête avec une clause WHERE pour ne sélectionner que les canidés :
SELECT
o.Name, p.Type, p.Name, p.Weight
FROM
animals_dataset.owners o
JOIN
animals_dataset.pets p
ON
o.OwnerID = p.OwnerID
WHERE
p.Type = "Canine";
Dans l'éditeur de requête, exécutez la même requête avec une clause ORDER BY pour trier les résultats par nom de propriétaire.
SELECT
o.Name, p.Type, p.Name, p.Weight
FROM
animals_dataset.owners o
JOIN
animals_dataset.pets p
ON
o.OwnerID = p.OwnerID
WHERE
p.Type = "Canine"
ORDER BY
o.Name ASC;
Dans l'éditeur de requête, exécutez la requête suivante pour compter le nombre d'animaux de compagnie par type :
SELECT
type, COUNT(*) AS count
FROM
animals_dataset.pets
GROUP BY
type
ORDER BY
count DESC;
La table pets contient 10 chiens, 5 chats, 2 cochons et 2 tortues.
Dans l'éditeur de requête, exécutez la requête suivante pour compter le nombre d'animaux de compagnie par propriétaire.
SELECT
o.Name, COUNT(p.Name) AS count
FROM
animals_dataset.owners o
JOIN
animals_dataset.pets p
ON
o.OwnerID = p.OwnerID
GROUP BY
o.Name
ORDER BY
count DESC;
Le propriétaire nommé Doug possède le plus d'animaux (quatre au total).
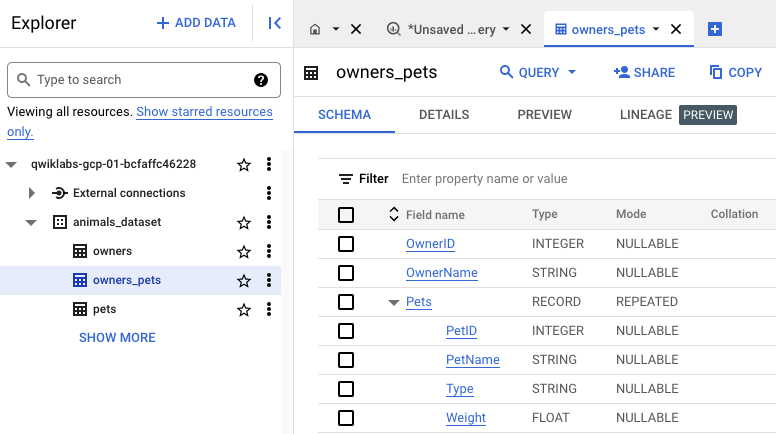
Dans l'éditeur de requête, exécutez la requête suivante pour renvoyer les informations sur les animaux de compagnie sous forme de champ imbriqué et répété :
SELECT
o.OwnerID,
o.Name AS OwnerName,
ARRAY_AGG(STRUCT(
p.Name AS PetName,
p.Type,
p.Weight)) AS Pets
FROM
animals_dataset.owners AS o
JOIN
animals_dataset.pets AS p
ON
o.OwnerID = p.OwnerID
GROUP BY
o.OwnerID, o.Name;
Note:
In BigQuery, nested and repeated fields are stored as `ARRAY`s of `STRUCT`s. La syntaxe "ARRAY_AGG(STRUCT…)" fournit les résultats sous forme de valeurs imbriquées et répétées, et permet de visualiser plus facilement les relations entre les données, car les valeurs jointes sont organisées clairement.
Une autre option SQL utile dans BigQuery consiste à utiliser une clause WITH pour définir des CTE et interroger les résultats d'une autre requête. Cette syntaxe évite d'utiliser des instructions SQL imbriquées et rend votre code plus lisible.
Dans l'éditeur de requête, exécutez la requête suivante pour définir une CTE basée sur la requête précédente :
WITH owners_pets AS (SELECT
o.OwnerID,
o.Name AS OwnerName,
ARRAY_AGG(STRUCT(
p.Name AS PetName,
p.Type,
p.Weight)) AS Pets
FROM
animals_dataset.owners AS o
JOIN
animals_dataset.pets AS p
ON
o.OwnerID = p.OwnerID
GROUP BY
o.OwnerID, o.Name)
SELECT
op.OwnerName, op.Pets
FROM
owners_pets AS op;
Cliquez sur Vérifier ma progression pour valider l'objectif.
Joindre des données et écrire des CTE à l'aide d'instructions SQL SELECT
Tâche 4 : Créer des tables et des vues à l'aide d'instructions LDD
Dans une tâche précédente, vous avez utilisé des instructions LDD pour créer des ensembles de données et des tables BigQuery. BigQuery permet aussi d'utiliser des instructions LDD pour créer des vues logiques et des vues matérialisées.
Pour en savoir plus sur l'utilisation d'instructions LDD pour créer des vues dans BigQuery, consultez la documentation Présentation des vues.
Dans cette tâche, vous allez utiliser des instructions LDD pour créer des tables, des vues logiques et des vues matérialisées.
Dans l'éditeur de requête, exécutez le code suivant pour écrire les résultats d'une requête dans une nouvelle table :
CREATE OR REPLACE TABLE
animals_dataset.owners_pets AS (
SELECT
o.OwnerID,
o.Name AS OwnerName,
ARRAY_AGG(STRUCT(
p.PetID,
p.Name AS PetName,
p.Type,
p.Weight)) AS Pets
FROM
animals_dataset.owners AS o
JOIN
animals_dataset.pets AS p
ON
o.OwnerID = p.OwnerID
GROUP BY
o.OwnerID, o.Name
);
Développez le volet "Explorateur" (panneau de gauche) qui liste l'ensemble de données et la table, puis cliquez sur le nom de la table owner_pets.
Cliquez sur l'onglet Schéma pour examiner le schéma de la table owners_pets que vous venez de créer.
Le schéma inclut un champ imbriqué et répété nommé Pets, qui contient l'identifiant, le nom, le type et le poids de chaque animal de compagnie pour chaque propriétaire.
Dans une tâche précédente, vous avez exécuté une requête qui a joint les tables owners et pets pour compter le nombre d'animaux de compagnie pour chaque propriétaire. Maintenant que les données sont contenues dans un champ imbriqué et répété, vous pouvez utiliser la fonction ARRAY_LENGTH pour renvoyer le nombre d'animaux de compagnie pour chaque propriétaire.
Dans l'éditeur de requête, exécutez la requête suivante pour renvoyer le nombre d'animaux de compagnie pour chaque propriétaire :
SELECT
OwnerName,
ARRAY_LENGTH(Pets) AS count
FROM
animals_dataset.owners_pets
ORDER BY
count DESC;
Dans l'éditeur de requête, exécutez la requête suivante pour créer une vue logique qui ne renvoie que les petits animaux de compagnie (qui pèsent jusqu'à 20 livres, soit 9 kg) :
CREATE OR REPLACE VIEW
animals_dataset.small_pets AS (
SELECT
*
FROM
animals_dataset.pets
WHERE
weight <= 20
);
Cliquez sur Accéder à la vue.
Dans le volet "Explorateur", cliquez sur Afficher les actions (icône à trois points verticaux) pour la vue small_pets, puis sélectionnez Requête.
Dans l'éditeur de requête, exécutez la requête suivante pour examiner les données de la vue :
SELECT
PetID, Weight
FROM
animals_dataset.small_pets;
Dans BigQuery, les vues matérialisées sont des vues précalculées qui mettent régulièrement en cache les résultats d'une requête pour améliorer les performances et l'efficacité. Les vues matérialisées peuvent être particulièrement utiles pour les requêtes qui nécessitent un traitement complexe, comme les agrégations.
Dans l'éditeur de requête, exécutez la requête suivante pour créer une vue matérialisée qui renvoie le poids total de chaque type d'animal :
CREATE OR REPLACE MATERIALIZED VIEW
animals_dataset.pet_weight_by_type AS (
SELECT
type,
SUM(Weight) AS total_weight
FROM
animals_dataset.pets
GROUP BY
type
);
Cliquez sur Accéder à la vue matérialisée.
Dans le volet "Explorateur", cliquez sur Afficher les actions (icône à trois points verticaux) pour la vue matérialisée pet_weight_by_type, puis sélectionnez "Requête".
Dans l'éditeur de requête, exécutez la requête suivante pour examiner les données de la vue matérialisée :
SELECT
type, total_weight
FROM
animals_dataset.pet_weight_by_type;
Les canidés ont le poids total le plus élevé : 314 livres, soit 142 kg.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer des tables et des vues à l'aide d'instructions LDD
Tâche 5 : Paramétrer des UDF et des procédures stockées personnalisées
Dans BigQuery, vous pouvez définir une UDF personnalisée dans les cas où aucune fonction intégrée ne répond à vos besoins. Une UDF accepte une ou plusieurs colonnes d'entrée, exécute des actions sur l'entrée et renvoie le résultat de ces actions en sortie. Vous pouvez également définir des procédures stockées comme des fonctions qui exécutent des collections d'instructions SQL, telles que SELECT, INSERT, etc., dans l'ordre souhaité.
Dans cette tâche, vous allez définir des UDF et des procédures stockées pour recalculer les valeurs existantes d'une table et faciliter l'ajout d'enregistrements de données à une table.
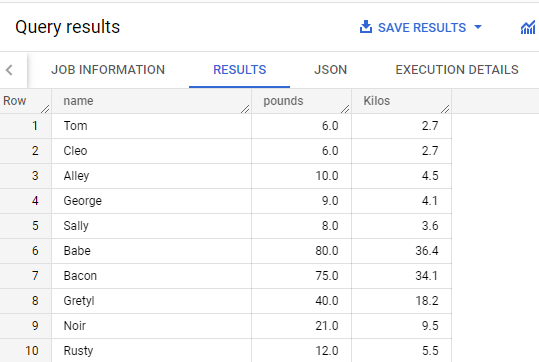
Dans l'éditeur de requête, exécutez le code suivant pour créer une UDF qui convertit les livres en kilogrammes :
CREATE OR REPLACE FUNCTION animals_dataset.PoundsToKilos(pounds FLOAT64)
AS (
round(pounds / 2.2, 1)
);
Dans l'éditeur de requête, exécutez la requête suivante pour tester l'UDF :
SELECT
name,
weight AS pounds,
animals_dataset.PoundsToKilos(Weight) AS Kilos
FROM
animals_dataset.pets;
Vous pouvez aussi créer une procédure stockée pour faciliter l'ajout d'un nouvel animal de compagnie. La procédure suivante recherche l'identifiant d'animal de compagnie le plus élevé dans la table pets et lui ajoute la valeur 1. Elle attribue ensuite cette nouvelle valeur à l'identifiant du nouvel animal de compagnie. Lorsque le nouvel animal de compagnie est ajouté, la valeur du nouvel identifiant est renvoyée.
Dans l'éditeur de requête, exécutez la requête suivante pour créer une procédure stockée permettant d'ajouter un animal de compagnie :
CREATE OR REPLACE PROCEDURE animals_dataset.create_pet(
customerID INT64, type STRING, name STRING, weight FLOAT64, out newPetID INT64)
BEGIN
SET newPetID = (SELECT MAX(PetID) + 1 FROM animals_dataset.pets);
INSERT INTO animals_dataset.pets (PetID, OwnerID, Type, Name, Weight)
VALUES(newPetID, customerID, type, name, weight);
END
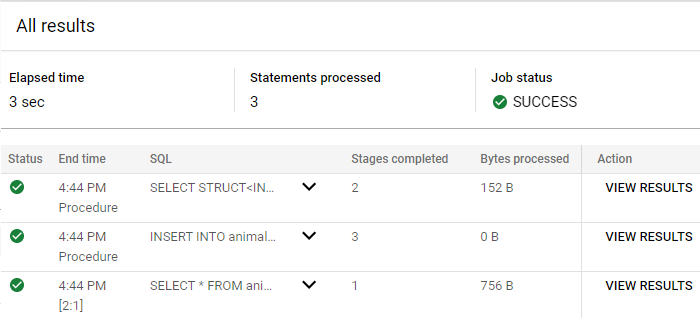
Dans l'éditeur de requête, exécutez la requête suivante pour tester la procédure stockée :
DECLARE newPetID INT64;
CALL animals_dataset.create_pet(1, 'Dog', 'Duke', 15.0, newPetID);
SELECT *
FROM
animals_dataset.pets
WHERE
PetID = newPetID;
Cliquez sur Afficher les résultats pour la dernière instruction SELECT *.
Vous constatez que la variable de sortie de la fonction correspond à l'enregistrement qui vient d'être créé pour un chien nommé Duke dont l'identifiant est 30.
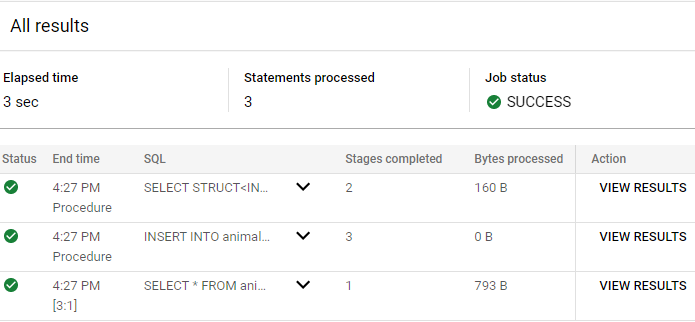
Dans l'éditeur de requête, exécutez la requête suivante pour ajouter un autre animal de compagnie :
DECLARE newPetID INT64;
CALL animals_dataset.create_pet(4, 'Cat', 'Fluffy', 6.0, newPetID);
SELECT *
FROM
animals_dataset.pets
WHERE
PetID = newPetID;
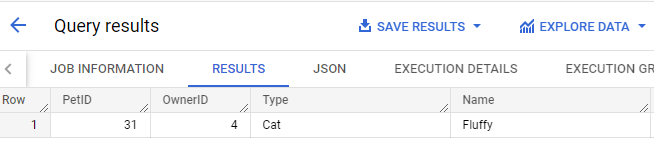
Cliquez sur Afficher les résultats pour la dernière instruction SELECT *.
Vous remarquez que la valeur du champ "ID" continue d'augmenter. Le nouvel identifiant correspondant au chat nommé Fluffy est 31.
Dans l'éditeur de requête, exécutez la requête suivante pour vérifier que les deux nouveaux animaux de compagnie ont été ajoutés à la table pets :
SELECT *
FROM
animals_dataset.pets
WHERE
Name in ('Duke', 'Fluffy');
Cliquez sur Vérifier ma progression pour valider l'objectif.
Paramétrer des UDF et des procédures stockées personnalisées
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Skills supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Voici à quoi correspond le nombre d'étoiles que vous pouvez attribuer à un atelier :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Le meilleur moyen d'exécuter cet atelier consiste à utiliser une fenêtre de navigation privée. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Dans cet atelier, vous allez créer des tables et des vues à l'aide d'instructions LDD, mettre à jour des tables à l'aide d'instructions LMD, joindre des données à l'aide de SQL, et paramétrer des fonctions définies par l'utilisateur (UDF) et des procédures stockées personnalisées.
Durée :
0 min de configuration
·
Accessible pendant 90 min
·
Terminé après 60 min




 ), puis sous "Analyse", cliquez sur BigQuery.
), puis sous "Analyse", cliquez sur BigQuery.