Questi contenuti non sono ancora ottimizzati per i dispositivi mobili.
Per un'esperienza ottimale, visualizza il sito su un computer utilizzando un link inviato via email.
Panoramica
I workflow sono un tema molto comune nell'analisi dei dati: implicano l'acquisizione, la trasformazione e l'analisi dei dati per individuare le informazioni significative al loro interno. In Google Cloud, per ospitare i workflow viene usato Cloud Composer, una versione in hosting del popolare strumento per workflow open source Apache Airflow.
In questo lab utilizzerai la console Google Cloud per configurare un ambiente Cloud Composer. Poi userai Cloud Composer per eseguire un semplice workflow che verifica l'esistenza di un file di dati, crea un cluster Cloud Dataproc, esegue un job di conteggio parole di Apache Hadoop nel cluster Cloud Dataproc ed elimina il cluster.
In questo lab proverai a:
Usare la console Google Cloud per creare l'ambiente Cloud Composer
Visualizzare ed eseguire il DAG (grafo diretto aciclico) nell'interfaccia web di Airflow
Visualizzare i risultati del job di conteggio parole in Storage
Configurazione e requisiti
Configurazione del lab
Per ciascun lab, riceverai un nuovo progetto Google Cloud e un insieme di risorse per un periodo di tempo limitato senza alcun costo aggiuntivo.
Accedi a Qwiklabs utilizzando una finestra di navigazione in incognito.
Tieni presente la durata dell'accesso al lab (ad esempio, 1:15:00) e assicurati di finire entro quell'intervallo di tempo.
Non è disponibile una funzionalità di pausa. Se necessario, puoi riavviare il lab ma dovrai ricominciare dall'inizio.
Quando è tutto pronto, fai clic su Inizia lab.
Annota le tue credenziali del lab (Nome utente e Password). Le userai per accedere a Google Cloud Console.
Fai clic su Apri console Google.
Fai clic su Utilizza un altro account e copia/incolla le credenziali per questo lab nei prompt.
Se utilizzi altre credenziali, compariranno errori oppure ti verranno addebitati dei costi.
Accetta i termini e salta la pagina di ripristino delle risorse.
Attiva Google Cloud Shell
Google Cloud Shell è una macchina virtuale in cui sono caricati strumenti per sviluppatori. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud.
Google Cloud Shell fornisce l'accesso da riga di comando alle risorse Google Cloud.
Nella barra degli strumenti in alto a destra della console Cloud, fai clic sul pulsante Apri Cloud Shell.
Fai clic su Continua.
Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Quando la connessione è attiva, l'autenticazione è già avvenuta e il progetto è impostato sul tuo PROJECT_ID. Ad esempio:
gcloud è lo strumento a riga di comando di Google Cloud. È preinstallato su Cloud Shell e supporta il completamento.
Puoi visualizzare il nome dell'account attivo con questo comando:
Prima di iniziare il tuo lavoro su Google Cloud, devi assicurarti che il tuo progetto disponga delle autorizzazioni corrette in Identity and Access Management (IAM).
Nella console Google Cloud, nel menu di navigazione (), seleziona IAM e amministrazione > IAM.
Conferma che l'account di servizio di computing predefinito {project-number}-compute@developer.gserviceaccount.com sia presente e che abbia il ruolo di editor assegnato. Il prefisso dell'account è il numero del progetto, che puoi trovare in Menu di navigazione > Panoramica di Cloud > Dashboard
Nota: se l'account non è presente in IAM o non dispone del ruolo editor, attieniti alla procedura riportata di seguito per assegnare il ruolo richiesto.
Nel menu di navigazione della console Google Cloud, fai clic su Panoramica di Cloud > Dashboard.
Copia il numero del progetto (es. 729328892908).
Nel menu di navigazione, seleziona IAM e amministrazione > IAM.
Nella parte superiore della tabella dei ruoli, sotto Visualizza per entità, fai clic su Concedi accesso.
In questa sezione, creerai l'ambiente Cloud Composer.
Nota: prima di andare avanti, assicurati di aver eseguito le attività precedenti per garantire che le API richieste siano abilitate correttamente. Se non l'hai ancora fatto, esegui queste attività ora, altrimenti la creazione dell'ambiente Cloud Composer non riuscirà.
Nella barra del titolo della console Google Cloud, digita Composer nel campo di ricerca, quindi fai clic su Composer nella sezione Prodotti e pagine.
Fai clic su Crea ambiente e seleziona Composer 3. Imposta quanto segue per l'ambiente:
Proprietà
Valore
Nome
highcpu
Località
Versione immagine
composer-3-airflow-n.n.n-build.n (Nota: seleziona l'immagine con il numero più alto disponibile)
Service account
xxxxx-compute@developer.gserviceaccount.com
Modalità di resilienza
Resilienza standard
Zona del database Airflow
In Risorse dell'ambiente, seleziona Piccolo.
Lascia invariate tutte le altre impostazioni predefinite.
Fai clic su Crea.
Il processo di creazione dell'ambiente è completato quando viene visualizzato il segno di spunta verde a sinistra del nome dell'ambiente nella pagina Ambienti della console.
Il completamento del processo di configurazione dell'ambiente può richiedere 15-30 minuti. Prosegui con il lab mentre l'ambiente viene avviato.
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Crea l'ambiente Cloud Composer.
Crea un bucket Cloud Storage
Crea un bucket Cloud Storage nel tuo progetto. Questo bucket verrà usato come output per il job Hadoop da Dataproc.
Vai a Menu di navigazione > Cloud Storage > Bucket e fai clic su + Crea.
Assegna al bucket un nome universalmente univoco, ad esempio l'ID progetto , poi fai clic su Crea. Se appare il messaggio L'accesso pubblico verrà vietato fai clic su Conferma.
Memorizza il nome del bucket Cloud Storage per utilizzarlo come variabile Airflow più avanti nel lab.
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Crea un bucket Cloud Storage.
Attività 3: Airflow e concetti principali
Mentre aspetti che l'ambiente Composer venga creato, rivediamo alcuni termini usati in Airflow.
Airflow è una piattaforma per creare, pianificare e monitorare i workflow in modo programmatico.
Usa Airflow per creare workflow come grafi diretti aciclici (DAG) di attività. Lo scheduler di Airflow esegue le attività su un array di worker in base alle dipendenze specificate.
Un grafo diretto aciclico (Directed Acyclic Graph, DAG) è una raccolta di tutte le attività da eseguire, organizzate in modo da riflettere le rispettive relazioni e dipendenze.
Un'esecuzione specifica di un'attività, caratterizzata come DAG, attività e point-in-time. Ha uno stato indicativo: running, success, failed, skipped…
Per saperne di più sui concetti di Airflow, consulta la documentazione.
Attività 4: definisci il workflow
Adesso parliamo del workflow che userai. I workflow di Cloud Composer sono composti da DAG (grafi diretti aciclici). I DAG sono definiti in file Python standard che si trovano nella cartella DAG_FOLDER di Airflow. Airflow esegue il codice in ogni file per creare in modo dinamico gli oggetti DAG. Puoi avere tutti i DAG che vuoi, ognuno dei quali descrive un numero qualsiasi di attività. In generale, ogni DAG deve corrispondere a un singolo workflow logico.
Di seguito è riportato il codice del workflow hadoop_tutorial.py, chiamato anche DAG:
"""Example Airflow DAG that creates a Cloud Dataproc cluster, runs the Hadoop
wordcount example, and deletes the cluster.
This DAG relies on three Airflow variables
https://airflow.apache.org/concepts.html#variables
* gcp_project - Google Cloud Project to use for the Cloud Dataproc cluster.
* gce_zone - Google Compute Engine zone where Cloud Dataproc cluster should be
created.
* gce_region - Google Compute Engine region where Cloud Dataproc cluster should be
created.
* gcs_bucket - Google Cloud Storage bucket to used as output for the Hadoop jobs from Dataproc.
See https://cloud.google.com/storage/docs/creating-buckets for creating a
bucket.
"""
import datetime
import os
from airflow import models
from airflow.providers.google.cloud.operators.dataproc import (
DataprocCreateClusterOperator,
DataprocDeleteClusterOperator,
DataprocSubmitJobOperator,
)
from airflow.utils.trigger_rule import TriggerRule
# Define the DAG's schedule using a cron expression for daily runs
DAILY_SCHEDULE = '0 0 * * *' # Runs at midnight every day
# Output file for Cloud Dataproc job.
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
# Path to Hadoop wordcount example available on every Dataproc cluster.
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
# Arguments to pass to Cloud Dataproc job.
wordcount_args = ['wordcount', 'gs://pub/shakespeare/rose.txt', output_file]
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
default_dag_args = {
# Setting start date as yesterday starts the DAG immediately when it is
# detected in the Cloud Storage bucket.
'start_date': yesterday,
# To email on failure or retry set 'email' arg to your email and enable
# emailing here.
'email_on_failure': False,
'email_on_retry': False,
# If a task fails, retry it once after waiting at least 5 minutes
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
with models.DAG(
dag_id='composer_hadoop_tutorial', # It's good practice to explicitly use 'dag_id'
schedule_interval=DAILY_SCHEDULE, # Using the new cron expression
default_args=default_dag_args) as dag:
# Create a Cloud Dataproc cluster.
create_dataproc_cluster = DataprocCreateClusterOperator(
task_id='create_dataproc_cluster',
# Give the cluster a unique name by appending the date scheduled.
# See https://airflow.apache.org/code.html#default-variables
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
region=models.Variable.get('gce_region'),
zone=models.Variable.get('gce_zone'),
image_version='2.0',
master_machine_type='e2-standard-2',
worker_machine_type='e2-standard-2')
# Run the Hadoop wordcount example installed on the Cloud Dataproc cluster
# master node.
run_dataproc_hadoop = DataprocSubmitJobOperator(
task_id='run_dataproc_hadoop',
region=models.Variable.get('gce_region'),
job={
"placement": {"cluster_name": 'composer-hadoop-tutorial-cluster-{{ ds_nodash }}'},
"hadoop_job": {
"main_jar_file_uri": WORDCOUNT_JAR,
"args": wordcount_args
}
}
)
# Delete Cloud Dataproc cluster.
delete_dataproc_cluster = DataprocDeleteClusterOperator(
task_id='delete_dataproc_cluster',
project_id=models.Variable.get('gcp_project'),
region=models.Variable.get('gce_region'),
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
# Setting trigger_rule to ALL_DONE causes the cluster to be deleted
# even if the Dataproc job fails.
trigger_rule=TriggerRule.ALL_DONE)
# Define DAG dependencies.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
Per orchestrare le tre attività del workflow, il DAG importa i seguenti operatori:
DataprocCreateClusterOperator: crea un cluster Cloud Dataproc.
DataprocSubmitJobOperator: invia un job di conteggio parole di Hadoop e scrive i risultati in un bucket Cloud Storage.
DataprocDeleteClusterOperator: elimina il cluster per evitare addebiti continui per Compute Engine.
Le attività vengono eseguite in sequenza, come puoi vedere in questa sezione del file:
# Define DAG dependencies.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
Il nome del DAG è composer_hadoop_tutorial e il DAG viene eseguito una volta al giorno:
with models.DAG(
'composer_hadoop_tutorial',
# Continue to run DAG once per day
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
Poiché la data di inizio specificata da start_date e passata a default_dag_args è impostato su yesterday, Cloud Composer pianifica il workflow in modo da eseguirlo subito dopo il caricamento del DAG.
Attività 5: visualizza le informazioni dell'ambiente
Torna a Composer per controllare lo stato dell'ambiente.
Una volta creato l'ambiente, fai clic sul suo nome (highcpu) per visualizzarne i dettagli.
Nella scheda Configurazione dell'ambiente vedrai informazioni come l'URL della UI web di Airflow, il cluster GKE e un link alla cartella DAG, che è archiviata nel tuo bucket.
Nota: Cloud Composer pianifica i workflow solo nella cartella /dags.
Attività 6: usa la UI di Airflow
Per accedere all'interfaccia web di Airflow mediante la console:
Torna alla pagina Ambienti.
Nella colonna Server web Airflow per l'ambiente, fai clic su Airflow.
Fai clic sulle credenziali del lab.
L'interfaccia web di Airflow si apre in una nuova finestra del browser.
Attività 7: imposta le variabili Airflow
Le variabili Airflow sono un concetto specifico di questa piattaforma e sono diverse dalle variabili di ambiente.
Nell'interfaccia di Airflow, seleziona Admin (Amministratore) > Variables (Variabili) dalla barra dei menu.
Fai clic sull'icona + per aggiungere un nuovo record.
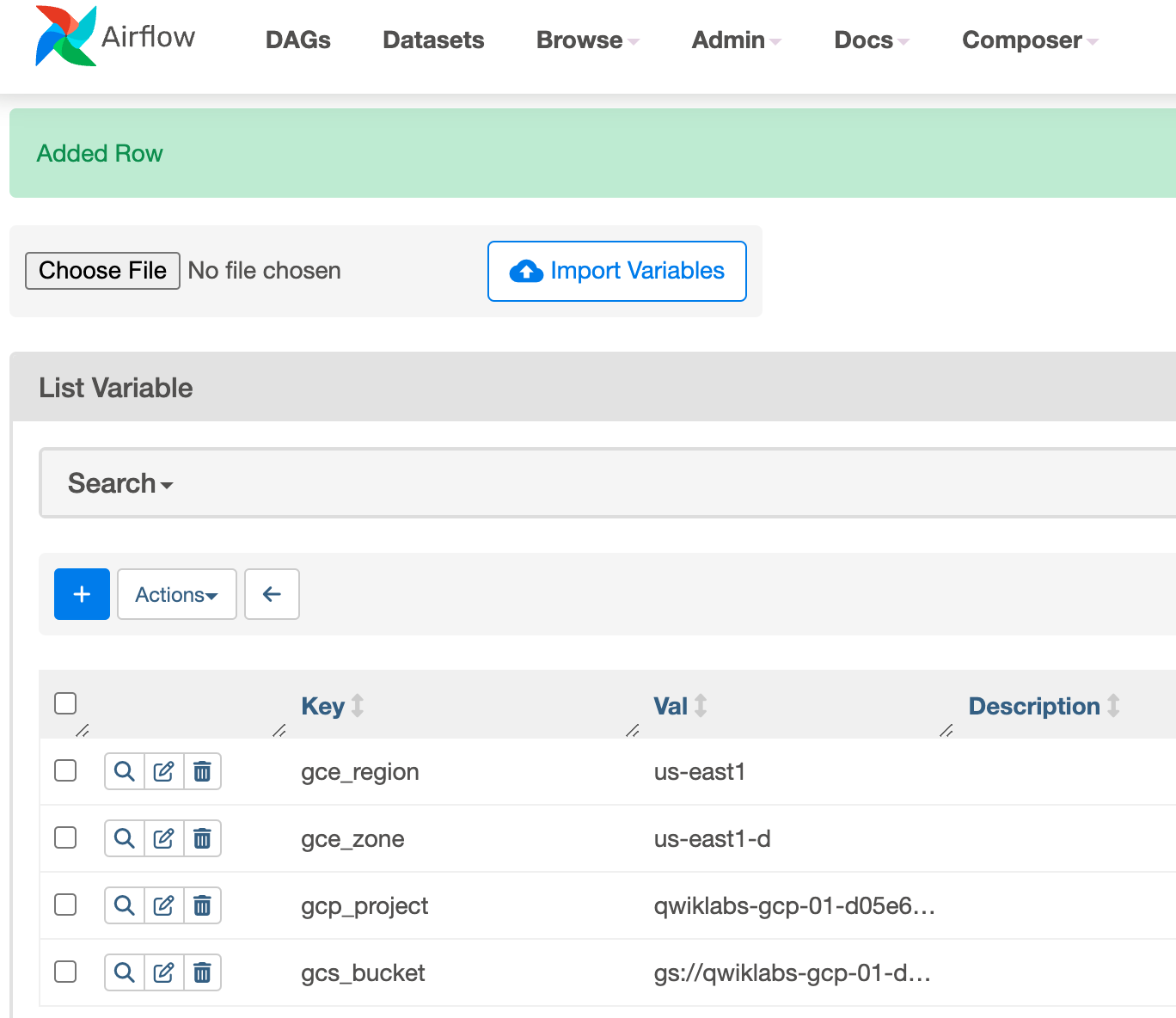
Crea le seguenti variabili Airflow: gcp_project, gcs_bucket, gce_zone e gce_region. Fai clic su Save (Salva) dopo ogni variabile.
Key (Chiave)
Val (Valore)
Details (Dettagli)
gcp_project
Il progetto Google Cloud utilizzato in questo lab.
gcs_bucket
gs://
In questo bucket viene archiviato l'output dei job Hadoop da Dataproc.
gce_zone
Questa è la zona Compute Engine in cui verrà creato il cluster Cloud Dataproc.
gce_region
Questa è la regione Compute Engine in cui verrà creato il cluster Cloud Dataproc.
Fai clic su Save (Salva). Dopo aver aggiunto la prima variabile, ripeti la stessa procedura per la seconda e la terza variabile. Al termine, questo dovrebbe essere l'aspetto della tabella delle variabili:
Attività 8: carica il DAG in Cloud Storage
Per caricare il DAG:
In Cloud Shell esegui il comando riportato di seguito per caricare una copia del file hadoop_tutorial.py nel bucket Cloud Storage generato automaticamente quando hai creato l'ambiente.
Sostituisci <DAGs_folder_path> con il percorso della cartella dei DAG in questo comando:
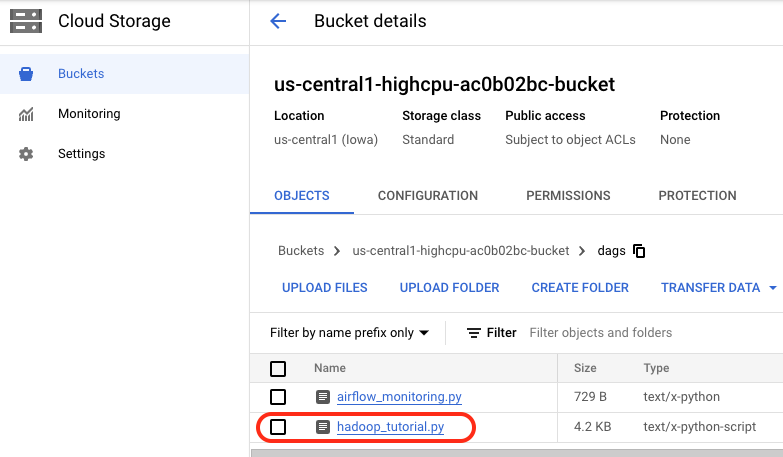
Dopo aver caricato il file nella directory dei DAG, apri la cartella dags nel bucket. Vedrai il file nella scheda Oggetti dei dettagli del bucket.
Quando un file DAG viene aggiunto alla cartella dei DAG, Cloud Composer aggiunge il DAG ad Airflow e lo pianifica automaticamente. Le modifiche ai DAG vengono applicate entro 3-5 minuti.
Puoi vedere lo stato dell'attività del DAG composer_hadoop_tutorial nell'interfaccia web di Airflow.
Nota: puoi ignorare senza problemi eventuali messaggi visualizzati nell'interfaccia, ad esempio "The scheduler does not appear to be running…" (Sembra che lo scheduler non sia in esecuzione). L'interfaccia web di Airflow viene aggiornata man mano che il DAG viene elaborato.
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Carica il DAG in Cloud Storage.
Esplora le esecuzioni del DAG
Quando carichi il file DAG nella cartella dags di Cloud Storage, Cloud Composer analizza il file. Se non vengono rilevati errori, il nome del workflow viene visualizzato nell'elenco di DAG e il workflow viene messo in coda per essere eseguito immediatamente.
Assicurati di trovarti nella scheda DAG dell'interfaccia web di Airflow. Il completamento di questo processo richiede vari minuti. Aggiorna il browser per assicurarti di visualizzare le informazioni più recenti.
In Airflow, fai clic su composer_hadoop_tutorial per aprire la pagina dei dettagli del DAG. Questa pagina include diverse rappresentazioni delle attività e delle dipendenze del workflow.
Fai clic su Graph (Grafo) nella barra degli strumenti. Passa il mouse sopra il grafo di ogni attività per visualizzarne lo stato. Puoi notare che il bordo attorno a ciascuna attività indica anche lo stato (bordo verde = in esecuzione; rosso = non riuscita e così via).
Fai clic sul link "Refresh" (Aggiorna) per assicurarti di visualizzare le informazioni più recenti. I bordi dei processi cambiano colore quando il rispettivo stato cambia.
Nota: se il cluster Dataproc esiste già, puoi eseguire nuovamente il workflow fino a quando non riesce facendo clic su "create_dataproc_cluster" e poi su Clear (Cancella) per reimpostare le tre attività. Fai clic su OK per confermare.
Quando lo stato per create_dataproc_cluster diventa "running", seleziona Menu di navigazione > Dataproc e fai clic su:
Cluster per monitorare la creazione e l'eliminazione del cluster. Il cluster creato dal workflow è temporaneo. Esiste solo per la durata del workflow e viene eliminato dall'ultima attività del workflow.
Job per monitorare il job di conteggio parole di Apache Hadoop. Fai clic sull'ID job per visualizzarne l'output del log.
Quando lo stato di Dataproc diventa "In esecuzione", torna ad Airflow e fai clic su Refresh (Aggiorna) per vedere che il cluster è completato.
Quando il processo run_dataproc_hadoop viene completato, seleziona Menu di navigazione > Cloud Storage > Bucket e fai clic sul nome del tuo bucket per vedere i risultati del conteggio parole nella cartella wordcount.
Una volta completati tutti i passaggi nel DAG, il bordo di ogni passaggio è verde scuro. Inoltre, il cluster Dataproc creato in precedenza è stato eliminato.
Per vedere il valore di una variabile, esegui il sottocomando dell'interfaccia a riga di comando di Airflow variables con l'argomento get oppure usa l'interfaccia web di Airflow.
Una volta completato il lab, fai clic su Termina lab. Google Cloud Skills Boost rimuove le risorse che hai utilizzato ed esegue la pulizia dell'account.
Avrai la possibilità di inserire una valutazione in merito alla tua esperienza. Seleziona il numero di stelle applicabile, inserisci un commento, quindi fai clic su Invia.
Il numero di stelle corrisponde alle seguenti valutazioni:
1 stella = molto insoddisfatto
2 stelle = insoddisfatto
3 stelle = esperienza neutra
4 stelle = soddisfatto
5 stelle = molto soddisfatto
Se non vuoi lasciare un feedback, chiudi la finestra di dialogo.
Per feedback, suggerimenti o correzioni, utilizza la scheda Assistenza.
Copyright 2026 Google LLC Tutti i diritti riservati. Google e il logo Google sono marchi di Google LLC. Tutti gli altri nomi di società e prodotti sono marchi delle rispettive società a cui sono associati.
I lab creano un progetto e risorse Google Cloud per un periodo di tempo prestabilito
I lab hanno un limite di tempo e non possono essere messi in pausa. Se termini il lab, dovrai ricominciare dall'inizio.
In alto a sinistra dello schermo, fai clic su Inizia il lab per iniziare
Utilizza la navigazione privata
Copia il nome utente e la password forniti per il lab
Fai clic su Apri console in modalità privata
Accedi alla console
Accedi utilizzando le tue credenziali del lab. L'utilizzo di altre credenziali potrebbe causare errori oppure l'addebito di costi.
Accetta i termini e salta la pagina di ripristino delle risorse
Non fare clic su Termina lab a meno che tu non abbia terminato il lab o non voglia riavviarlo, perché il tuo lavoro verrà eliminato e il progetto verrà rimosso
Questi contenuti non sono al momento disponibili
Ti invieremo una notifica via email quando sarà disponibile
Bene.
Ti contatteremo via email non appena sarà disponibile
Un lab alla volta
Conferma per terminare tutti i lab esistenti e iniziare questo
Utilizza la navigazione privata per eseguire il lab
Il modo migliore per eseguire questo lab è utilizzare una finestra del browser in incognito o privata. Ciò evita eventuali conflitti tra il tuo account personale e l'account studente, che potrebbero causare addebiti aggiuntivi sul tuo account personale.
In questo lab creerai un ambiente Cloud Composer utilizzando la console Google Cloud. Poi userai l'interfaccia web di Airflow per eseguire un workflow che verifica un file di dati, crea ed esegue un job di conteggio parole di Apache Hadoop su un cluster Dataproc ed elimina il cluster.
Durata:
Configurazione in 0 m
·
Accesso da 90 m
·
Completamento in 90 m



 ), seleziona IAM e amministrazione > IAM.
), seleziona IAM e amministrazione > IAM.