GSP1298

Visão geral
Imagine que você é um engenheiro de dados da Cymbal Gaming. Você e a equipe de desenvolvimento estão criando um jogo de eSports: o Desafio Interestelar. Esse jogo gera dados em tempo real com base em partidas entre dois jogadores de equipes diferentes. Por exemplo, dois jogadores competem em um evento. Um vencedor é anunciado e, em seguida, o jogador e a equipe vencedores recebem os pontos. Você precisa criar uma solução para lidar com esses dados transmitidos por streaming. Para isso, decide usar um pipeline do Dataflow para ingerir dados do Pub/Sub, transformá-los usando código Python e armazenar os resultados em tabelas do BigQuery. Essas tabelas são usadas para apresentar os resultados em painéis de jogadores e equipes.
Você leu que o Pub/Sub, o Dataflow e o BigQuery podem ser usados para esse tipo de caso de uso. Você também aprendeu que o Gemini pode ser útil ao longo do caminho. Por exemplo, se você tiver dificuldade ao escrever um novo comando, poderá usar o Code Assist para revisar e depurar seu código. Ele também pode dar sugestões para ajudar você a resolver problemas. Com esses recursos, você será mais independente no trabalho e, talvez, até mais eficiente. Entretanto, você não sabe bem como começar.
No início do laboratório, você vai encontrar no ambiente os recursos mostrados no diagrama a seguir.
Ao final do laboratório, você terá usado a arquitetura para realizar várias tarefas.
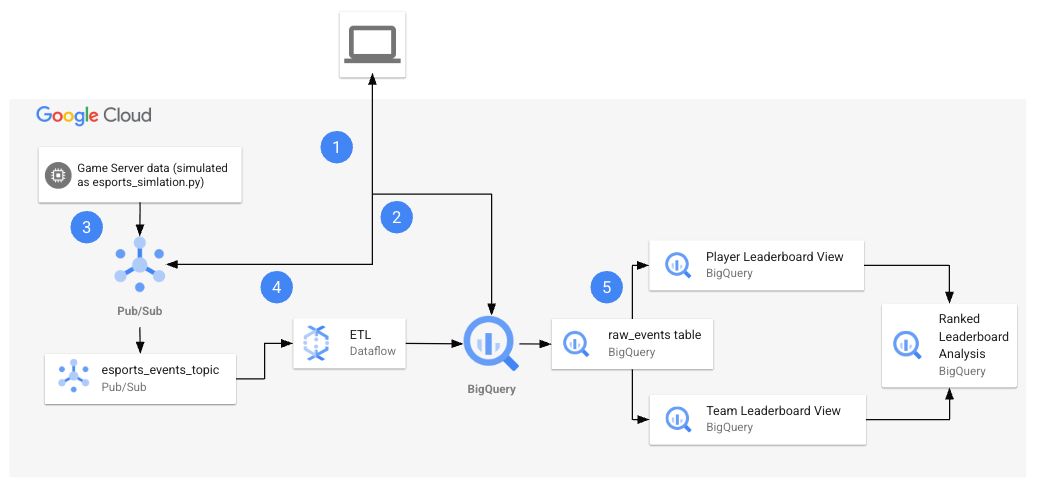
Confira na tabela a seguir uma explicação detalhada de cada tarefa referente à arquitetura do laboratório.
| Número da tarefa |
Detalhes |
| 1. |
Configurar variáveis de ambiente no Cloud Shell. |
| 2. |
Criar os recursos em nuvem:
você vai usar comandos do Cloud Shell para criar o tópico e a assinatura do Pub/Sub e o conjunto de dados do BigQuery. |
| 3. |
Recuperar os arquivos Python do repositório:
você vai recuperar esses arquivos e configurá-los para seu projeto. |
| 4. |
Gerar dados sintéticos e executar o pipeline:
após configurar os arquivos Python, você vai executá-los para gerar dados sintéticos e iniciar o pipeline. O arquivo "esports-simulation.py" usa Python para gerar mensagens contínuas do Pub/Sub para eventos de jogos. Em seguida, execute o arquivo "esports-pipeline.py". A execução desse arquivo inicia um pipeline do Dataflow que ingere as mensagens, as transforma e registra os resultados nas tabelas "raw_events", "player_score_updates" e "team_score_updates" no BigQuery. |
| 5. |
Verificar os resultados no BigQuery:
agora que você consumiu e transformou os dados e gravou os registros nas tabelas do BigQuery, é hora de conferir os resultados. Você vai executar consultas em cada tabela para analisar e visualizar os resultados. |
Objetivos
Neste laboratório, você vai aprender a:
- configurar as variáveis de ambiente;
- criar os recursos em nuvem;
- recuperar arquivos Python do repositório e modificá-los para seu projeto;
- gerar dados sintéticos e executar o pipeline;
- verificar os resultados no BigQuery.
Por fim, pense sobre o que você aprendeu neste laboratório e considere como abordar seus próprios casos de uso com dados de streaming. Depois, responda às perguntas do seu Diário do laboratório.
Configuração e requisitos
Antes de clicar no botão Começar o Laboratório
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é ativado quando você clica em Iniciar laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, e não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
Observação: para executar este laboratório, use o modo de navegação anônima (recomendado) ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e de estudante, o que poderia causar cobranças extras na sua conta pessoal.
- Tempo para concluir o laboratório: não se esqueça que, depois de começar, não será possível pausar o laboratório.
Observação: use apenas a conta de estudante neste laboratório. Se usar outra conta do Google Cloud, você poderá receber cobranças nela.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar por ele, uma caixa de diálogo vai aparecer para você selecionar a forma de pagamento.
No painel Detalhes do Laboratório, à esquerda, você vai encontrar o seguinte:
- O botão Abrir Console do Google Cloud
- O tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações, se forem necessárias
-
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer Login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
-
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Username"}}}
Você também encontra o nome de usuário no painel Detalhes do Laboratório.
-
Clique em Próxima.
-
Copie a Senha abaixo e cole na caixa de diálogo de Olá.
{{{user_0.password | "Password"}}}
Você também encontra a senha no painel Detalhes do Laboratório.
-
Clique em Próxima.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais.
-
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.
Observação: para acessar os produtos e serviços do Google Cloud, clique no Menu de navegação ou digite o nome do serviço ou produto no campo Pesquisar.

Tarefa 1: configurar variáveis de ambiente no Cloud Shell
Nesta tarefa, você configura variáveis de ambiente no Cloud Shell.
-
Abra o Cloud Shell.
-
Como é a primeira vez que o Cloud Shell é usado neste laboratório, você precisa autorizar o uso. Para fazer isso, clique em Autorizar na janela pop-up.
-
Execute estes comandos:
export PROJECT_ID="{{{project_0.project_id|set at lab start}}}"
export REGION="{{{project_0.default_region|set at lab start}}}"
export BUCKET_NAME="{{{project_0.project_id|set at lab start}}}-bucket"
-
Execute estes comandos para confirmar se as variáveis foram armazenadas:
echo ${PROJECT_ID}
echo ${REGION}
echo ${BUCKET_NAME}
Tarefa 2: criar os recursos em nuvem
Nesta tarefa, você usa o Cloud Shell para criar os recursos em nuvem, incluindo o tópico e a assinatura do Pub/Sub e o conjunto de dados do BigQuery.
Criar os recursos em nuvem
No Cloud Shell:
-
Execute este comando para criar o tópico do Pub/Sub:
gcloud pubsub topics create esports_events_topic
-
Execute este comando para criar a assinatura do Pub/Sub:
gcloud pubsub subscriptions create esports_events_topic-sub --topic=esports_events_topic
-
Execute este comando para criar o conjunto de dados do BigQuery:
bq --location=US mk --dataset esports_analytics
Confirmar a criação dos recursos
-
Você encontra uma função de pesquisa na parte de cima do console. Digite Pub/Sub nesse campo e clique em Pub/Sub nas opções listadas. Os tópicos do Pub/Sub são listados, incluindo o esports_events_topic.
-
Clique em esports_events_topic, que é o ID do tópico. A guia "Assinaturas" aparece para o tópico, e a assinatura esports_events_topic-sub é listada. Isso confirma a criação do tópico e da assinatura.
-
Volte para a função de pesquisa na parte de cima do console. Digite BigQuery nesse campo e clique em BigQuery nas opções listadas. Na página "Este é o BigQuery Studio", aparece um pop-up com a mensagem Olá! Este é o BigQuery no console do Cloud.
-
Clique em Concluído.
-
No painel "Explorador", abra seu projeto.
-
Você encontra o conjunto de dados esports_analytics na parte de baixo da lista. Isso confirma a criação do conjunto de dados do BigQuery.
Clique em Verificar meu progresso para conferir o objetivo.
Criar os recursos em nuvem
Tarefa 3: recuperar e configurar os arquivos Python
Nesta tarefa, você usa o wget no Cloud Shell para recuperar os arquivos Python de um bucket público do Cloud Storage. Depois da recuperação, abra os arquivos no editor do Cloud Shell e use o recurso Code Assist do Gemini para explicar como cada arquivo funciona. Por fim, use o editor do Cloud Shell para configurar os arquivos com detalhes do seu projeto e do bucket do Cloud Storage.
Recuperar os arquivos Python
-
Volte ao Cloud Shell.
-
Execute este comando para retornar ao diretório principal:
cd ~
-
Crie e acesse o diretório esports:
mkdir esports
cd esports
-
Recupere os arquivos Python usando estes comandos wget:
wget https://storage.googleapis.com/spls/gsp1298/esports-simulation.py
wget https://storage.googleapis.com/spls/gsp1298/esports-pipeline.py
No terminal, você recebe a confirmação de que os arquivos foram baixados.
Usar o Code Assist para explicar o que o arquivo Python faz
-
Clique no botão "Abrir editor" no Cloud Shell. Após essa ação, você verá o editor do Cloud Shell e o painel do Gemini Code Assist.
-
Feche a guia "Tutorial".
-
No painel "Explorador", abra a pasta esports. Você verá os arquivos Python.
-
Abra o arquivo esports-simulation.py.
-
No canto superior direito do arquivo, clique na seta ao lado de Gemini  .
.
-
Clique em Selecionar projeto do Gemini Code Assist para escolher o projeto a ser usado no Gemini. Na lista, selecione ID do projeto.
-
Na parte de baixo do painel do Gemini Code Assist, você pode inserir comandos onde aparece "Peça ao Gemini". Insira o seguinte comando:
Revise o código do arquivo "esports-simulation.py". Quero saber o que esse código faz.
O Code Assist explica com detalhes o que o código faz. De modo geral, o código simula uma partida de eSports com eventos e os publica em um tópico do Google Cloud Pub/Sub.
-
Siga o mesmo processo para saber o que o arquivo esports-pipeline.py faz usando este comando:
Revise o código do arquivo "esports-pipeline.py". Quero saber o que esse código faz.
Momento de reflexão
- Considerando seus dados e casos de uso, pense em como você usaria o Python para gerar dados sintéticos ou coletar informações dos seus aplicativos e, em seguida, publicar esses dados como mensagens do Pub/Sub em um tópico no seu próprio fluxo de trabalho de desenvolvimento. Anote suas respostas no diário do laboratório.
Observação: o Gemini foi usado para ajudar o desenvolvedor que criou o arquivo "esports-simulation.py". Peça ajuda ao Gemini para gerar dados de streaming sintéticos com Python para seus projetos. Além disso, use o Code Assist para explicar e resolver problemas no seu código.
-
Com suas próprias palavras, explique: o que o arquivo "esports-pipeline.py" faz?
-
Considerando seus dados e casos de uso, pense em como você usaria um pipeline do Dataflow para consumir mensagens do Pub/Sub, transformar os dados nelas e armazenar os resultados no BigQuery.
Clique em Verificar meu progresso para conferir o objetivo.
Recuperar e configurar os arquivos Python
Configurar os arquivos para o projeto e o bucket
No arquivo esports-pipeline.py:
-
Por volta da linha 11, defina a variável PROJECT_ID com o ID do projeto. Você pode encontrar isso na parte de cima do console do Google Cloud ou substituir a linha por este código:
PROJECT_ID = "{{{project_0.project_id|set at lab start}}}"
-
Por volta da linha 18, defina a variável GCS_TEMP_LOCATION com o nome do seu bucket do Cloud Storage. O nome do bucket foi informado no início. A linha gerada deve ser parecida com esta:
GCS_TEMP_LOCATION = "gs://{{{project_0.project_id|set at lab start}}}-bucket/temp"
-
Por volta da linha 19, defina a variável REGION com a região padrão do laboratório. Você pode encontrar isso nos detalhes do painel do laboratório ou substituir a linha por este código:
REGION = "{{{project_0.default_region|set at lab start}}}"
-
Salve o arquivo.
-
Volte para o arquivo esports-simulation.py.
-
Por volta da linha 10, defina a variável PROJECT_ID com o ID do projeto. Assim como no outro arquivo, basta substituir a linha por este código:
PROJECT_ID = "{{{project_0.project_id|set at lab start}}}"
Observação: se você não modificar os arquivos do seu projeto, vai encontrar erros no ambiente de execução do Cloud Shell ao executar esses arquivos na próxima tarefa.
-
Salve o arquivo.
Tarefa 4: gerar dados sintéticos e executar o pipeline
Nesta tarefa, você executa os arquivos Python para gerar os dados sintéticos e executar o pipeline.
Instalar as dependências e executar o simulador
-
Volte ao terminal do Cloud Shell.
-
Confirme se você está no diretório principal:
cd ~
-
Acesse o diretório esports:
cd esports
-
Use o PIP para instalar as dependências, mais especificamente a biblioteca Python para Pub/Sub:
pip install google-cloud-pubsub
-
Execute o simulador. Esse script será executado continuamente, enviando eventos para o tópico do Pub/Sub:
python3 esports-simulation.py
Você verá uma saída indicando que os eventos estão sendo publicados no terminal. Mantenha esse terminal aberto e em execução.
Confirmar se as mensagens foram publicadas no tópico no console do Pub/Sub
-
Use a função de pesquisa na parte de cima do console. Desta vez, pesquise "Pub/Sub" e clique em Pub/Sub na lista.
-
Clique em esports_events_topic, que é o ID do tópico. A guia "Assinaturas" aparece para o tópico, e a assinatura esports_events_topic-sub é listada.
-
Clique em esports_events_topic-sub, que é o ID da assinatura.
-
Na página de detalhes da assinatura esports_events_topic-sub, clique na guia Mensagens. Você vai ver isto: "Clique em "Pull" para ver as mensagens e atrasar temporariamente a entrega de mensagens para outros assinantes".
-
Clique em Pull. Se você vir mensagens listadas aqui, isso confirma que aquelas geradas pelo arquivo esports-simulation.py estão sendo recebidas pelo Pub/Sub. Clique no botão Ver o conteúdo para conferir uma das mensagens.
Tentar executar o pipeline do Dataflow
-
Abra uma nova guia do Cloud Shell. Clique no ícone "+" na barra do terminal do Cloud Shell para abrir um segundo terminal.
-
Confirme se você está no diretório principal:
cd ~
-
Acesse o diretório esports:
cd esports
-
Instale as dependências do Python para o Dataflow (apache-beam). No novo terminal, configure um ambiente virtual e instale as bibliotecas necessárias:
python3 -m venv df-env
source df-env/bin/activate
pip install apache-beam[gcp]
-
Tente iniciar o pipeline do Dataflow. Execute o script do pipeline usando o comando abaixo. Verifique se você também definiu as variáveis de ambiente PROJECT_ID e BUCKET_NAME no novo terminal.
export PROJECT_ID="{{{project_0.project_id|set at lab start}}}"
export BUCKET_NAME="{{{project_0.project_id|set at lab start}}}-bucket"
python3 esports-pipeline.py \
--project=$PROJECT_ID \
--region={{{project_0.default_region | Region}}} \
--runner=DataflowRunner \
--streaming \
--temp_location=gs://$BUCKET_NAME/temp \
--job_name=esports-leaderboard-pipeline
Esse comando envia o job para o serviço do Dataflow. Vai levar alguns minutos até que o job seja iniciado e comece a processar os dados.
Entretanto, neste ponto, você verá um aviso e erros como estes:
AVISO:apache_beam.options.pipeline_options: o bucket especificado em "staging_location" tem a política de exclusão reversível ativada. Para evitar cobranças desnecessárias relacionadas ao armazenamento, desative o recurso de exclusão reversível nos buckets que os jobs do Dataflow usam para armazenamento temporário e de preparação. Para mais informações, acesse este site: https://cloud.google.com/storage/docs/use-soft-delete#remove-soft-delete-policy.
ERROR:apache_beam.runners.dataflow.dataflow_runner:2025-07-11T14:50:27.572Z: JOB_MESSAGE_ERROR: o agente de serviço do Dataflow não pode acessar a conta de serviço do worker. Verifique se a API Dataflow está ativada no seu projeto. Além disso, confirme se o principal do agente do Dataflow tem o papel "Agente de serviço do Cloud Dataflow" na conta de serviço do worker. Para conceder esse papel, acesse https://cloud.google.com/iam/docs/manage-access-service-accounts#view-access. Na página "Contas de serviço", selecione a conta do worker, abra a guia "Permissões" e selecione "Incluir concessões de papel fornecidas pelo Google" para verificar os papéis. Para saber mais sobre esse tipo de conta, acesse https://cloud.google.com/dataflow/docs/concepts/security-and-permissions#permissions
O que isso significa? Primeiro, vamos começar com o aviso.
O aviso indica que o bucket usado neste laboratório, -bucket, precisa ter o recurso de proteção contra exclusão reversível desativado. Recomendamos que você desative essa opção. Abaixo, você encontra as instruções para fazer isso.
Agora, vamos abordar o erro. O que isso significa?
Há duas causas possíveis para esse erro.
-
A API Dataflow não está ativada. Entretanto, ativamos essa opção para você no início do laboratório. Para confirmar isso, acesse "APIs e serviços".
-
A causa real do erro é esta: você precisa adicionar o papel Agente de serviço do Cloud Dataflow à conta de serviço do Cloud Compute. A seguir, você encontra instruções para realizar essa tarefa.
Desativar o recurso de exclusão reversível no bucket do Cloud Storage
-
Use a função de pesquisa na parte de cima do console. Pesquise "Cloud Storage" e clique na opção Cloud Storage na lista. A página Visão geral é aberta.
-
Clique em Buckets. A página "Buckets" é exibida, e o bucket -bucket aparece na lista.
-
Clique em -bucket. A página de detalhes do bucket é aberta.
-
Clique em Proteção. Você verá uma lista de opções, incluindo Política de exclusão reversível (para recuperação de dados).
-
Clique em Desativar. Você verá uma janela pop-up com a opção Desativar política de exclusão reversível.
-
Clique em Confirmar. A política de exclusão reversível já está desativada.
Como adicionar o papel "Agente de serviço do Cloud Dataflow"
-
Use a função de pesquisa na parte de cima do console para acessar o IAM. A página do IAM é aberta.
-
Clique em Contas de serviço. A lista delas é exibida. Uma das contas listadas é a do Compute Engine. Sua conta de serviço do Compute Engine seria parecida com esta:
655017706949-compute@developer.gserviceaccount.com
-
Para adicionar o papel "Agente de serviço do Cloud Dataflow" a essa conta, clique em Ações ao lado dela.
-
Na lista de opções, clique em Gerenciar permissões.
-
Em "Gerenciar permissões da conta de serviço", clique em Gerenciar acesso. O papel de Editor já está incluído.
-
Clique em + Adicionar outro papel.
-
Use a opção "Selecionar papel". Pesquise e selecione o papel Agente de serviço do Cloud Dataflow.
-
Clique em Salvar.
-
Confirme se o papel foi adicionado.
Executar o pipeline do Dataflow
-
Volte ao Cloud Shell.
-
Confirme se você está na guia do segundo terminal, aquela para executar o pipeline do Dataflow (esports-pipeline.py).
-
Execute este comando mais uma vez:
export PROJECT_ID="{{{project_0.project_id|set at lab start}}}"
export BUCKET_NAME="{{{project_0.project_id|set at lab start}}}-bucket"
python3 esports-pipeline.py \
--project=$PROJECT_ID \
--region={{{project_0.default_region | Region}}} \
--runner=DataflowRunner \
--streaming \
--temp_location=gs://$BUCKET_NAME/temp \
--job_name=esports-leaderboard-pipeline
Desta vez, você vê esta mensagem: "O escalonamento automático está ativado para o Dataflow Streaming Engine. Os workers serão escalonados entre 1 e 100, a menos que maxNumWorkers seja especificado".
Isso significa que você resolveu a questão do aviso de exclusão reversível e do erro do agente de serviço do Cloud Dataflow.
Acessar o serviço do Dataflow e observar o pipeline
-
Use a função de pesquisa na parte de cima do console para pesquisar e selecionar o serviço do Dataflow. A página "Jobs" é exibida com dois jobs de mesmo nome. Um está em execução e o outro falhou.
-
Clique no job em execução para ver o gráfico dele. Na parte de baixo da página, você vê o painel "Registros".
-
Abra esse painel. Você vê as guias "Registros do job" e "Registros de worker".
-
Clique em Registros de worker.
-
Analise os registros fornecidos. Se você vir registros indicando que as tabelas "raw_events", "player_score_updates" e "team_score_updates" foram criadas, poderá seguir para a próxima tarefa.
Observação: pode levar de 5 a 7 minutos para que esses registros apareçam nas tabelas que estão sendo criadas.
Clique em Verificar meu progresso para conferir o objetivo.
Gerar dados sintéticos e executar o pipeline
Tarefa 5: verificar os resultados no BigQuery
Nesta tarefa, você executa consultas SQL para verificar os resultados das mensagens processadas. Para fazer isso, você precisa criar duas visualizações e, em seguida, consultar essas visualizações para exibir os rankings dos jogadores e das equipes. Também é preciso pensar sobre como o Looker pode ser usado para melhorar as visualizações desse ranking.
Criar as visualizações no BigQuery
-
Volte ao BigQuery.
-
No "Explorador", abra o projeto e selecione o conjunto de dados esports_analytics.
-
Clique em + (sinal de mais) para criar uma consulta.
-
Na guia da consulta, insira:
-- Query 1: Create the Player Leaderboard View
-- This view finds the most recent score for each player and ranks them.
CREATE OR REPLACE VIEW `esports_analytics.player_leaderboard_live` AS
SELECT
-- Use the RANK() window function to calculate the rank in real-time
RANK() OVER (ORDER BY total_score DESC) as rank,
player_id,
total_score,
last_updated
FROM (
-- This subquery gets only the single most recent score for each player
SELECT
player_id,
total_score,
last_updated,
ROW_NUMBER() OVER (PARTITION BY player_id ORDER BY last_updated DESC) as rn
FROM
`esports_analytics.player_score_updates`
)
WHERE rn = 1;
-- Query 2: Create the Team Leaderboard View
-- This view finds the most recent score for each team and ranks them.
CREATE OR REPLACE VIEW `esports_analytics.team_leaderboard_live` AS
SELECT
-- Use the RANK() window function to calculate the rank in real-time
RANK() OVER (ORDER BY total_wins DESC) as rank,
team_id,
total_wins,
last_updated
FROM (
-- This subquery gets only the single most recent score for each team
SELECT
team_id,
total_wins,
last_updated,
ROW_NUMBER() OVER (PARTITION BY team_id ORDER BY last_updated DESC) as rn
FROM
`esports_analytics.team_score_updates`
)
WHERE rn = 1;
Essa consulta cria duas visualizações: uma para o ranking dos jogadores e outra para o das equipes. Ela encontra as pontuações mais recentes do jogador e do time e os classifica de acordo com isso.
Executar uma consulta para exibir o ranking dos jogadores
-
Clique no sinal de mais (+) para criar uma consulta.
-
Na guia da consulta, insira:
SELECT * FROM `esports_analytics.player_leaderboard_live` ORDER BY rank;
Executar uma consulta para exibir o ranking da equipe
-
Clique no sinal de mais (+) para criar uma consulta.
-
Na guia da consulta, insira:
SELECT * FROM `esports_analytics.team_leaderboard_live` ORDER BY rank;
Momento de reflexão
Usando seu diário, responda às seguintes perguntas:
- Qual jogador está em primeiro lugar?
- Qual equipe está em primeiro lugar?
Clique em Verificar meu progresso para conferir o objetivo.
Verificar os resultados no BigQuery
Parabéns!
Você criou recursos do Google Cloud para oferecer suporte ao pipeline do Dataflow de eSports, incluindo um tópico e uma assinatura do Pub/Sub, um conjunto de dados, tabelas e visualizações do BigQuery e o próprio pipeline usando dados simulados gerados por scripts Python. Você também usou o Code Assist para entender melhor o código nesses scripts. A cada dia, você se torna mais confiante com o Google Cloud e pode usar o Gemini para complementar seu conhecimento e suas habilidades com fluxos de trabalho de engenharia de dados.
Próximas etapas / Saiba mais
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 11 de agosto de 2025
Laboratório testado em 11 de agosto de 2025
Copyright 2025 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.






