GSP1298

Présentation
Supposons que vous soyez ingénieur de données chez Cymbal Gaming. Avec l'équipe de développement, vous créez un nouveau jeu d'e-sport : Galactic Grand Prix. Le jeu génère des données en temps réel basées sur des parties en un contre un entre deux joueurs de différentes équipes. Par exemple, deux joueurs s'affrontent lors d'un événement, un vainqueur est désigné, et des points sont attribués au joueur et à l'équipe gagnants. Vous devez concevoir une solution pour gérer ces données en flux continu. Pour cela, vous allez utiliser un pipeline Dataflow afin d'ingérer les données depuis Pub/Sub, de les transformer à l'aide de code Python et de stocker les résultats dans des tables BigQuery. Ces tables serviront ensuite à visualiser les résultats sous forme de tableaux de bord pour les joueurs et les équipes.
Vous avez vu que Pub/Sub, Dataflow et BigQuery peuvent être utilisés pour ce type de cas d'utilisation. Vous avez également appris que Gemini peut vous aider tout au long du processus. Par exemple, si vous rencontrez des difficultés au moment d'écrire une nouvelle requête, vous pouvez utiliser Code Assist pour examiner et déboguer votre code. Gemini peut même vous fournir des suggestions pour résoudre des problèmes. L'utilisation de ces fonctionnalités vous permettra d'être plus autonome dans votre travail et, potentiellement, de gagner en efficacité. Toutefois, vous ne savez pas par où commencer.
Lorsque vous démarrerez l'atelier, l'environnement contiendra les ressources illustrées dans le diagramme suivant.
À la fin de l'atelier, vous aurez utilisé l'architecture pour effectuer plusieurs tâches.
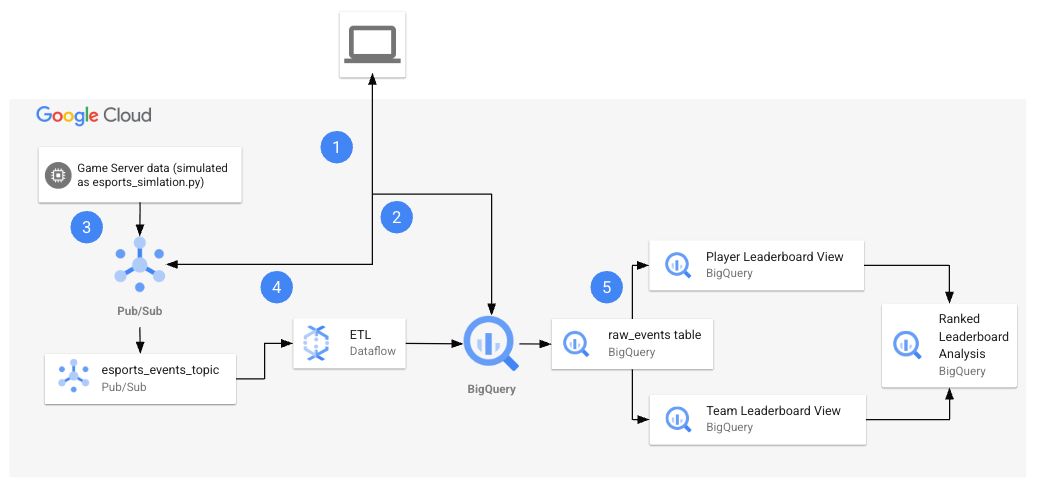
Le tableau suivant fournit une explication détaillée de chaque tâche par rapport à l'architecture de l'atelier.
| Tâche numérotée |
Détails |
| 1. |
Configurer des variables d'environnement dans Cloud Shell. |
| 2. |
Créer les ressources cloud :
Vous allez utiliser des commandes Cloud Shell pour créer le sujet et l'abonnement Pub/Sub, ainsi que l'ensemble de données BigQuery. |
| 3. |
Récupérer les fichiers Python à partir du dépôt :
Dans cette tâche, vous allez récupérer les fichiers Python à partir du dépôt et les configurer pour votre projet. |
| 4. |
Générer des données synthétiques et exécuter le pipeline :
Une fois les fichiers Python configurés pour votre projet, vous les exécuterez pour générer des données synthétiques et lancer le pipeline. Le fichier esports-simulation.py utilise Python afin de générer en continu des messages Pub/Sub pour les événements de jeu. Vous pouvez ensuite exécuter le fichier esports-pipeline.py pour lancer un pipeline Dataflow qui ingère les messages, les transforme et enregistre les résultats dans les tables raw_events, player_score_updates et team_score_updates de BigQuery. |
| 5. |
Vérifier les résultats dans BigQuery :
Maintenant que vous avez consommé et transformé les données, et stocké les résultats dans les tables de BigQuery, il est temps de vérifier ces résultats. Vous allez exécuter des requêtes sur chaque table afin d'analyser et d'afficher les résultats. |
Objectifs
Dans cet atelier, vous allez apprendre à :
- Configurer les variables d'environnement
- Créer les ressources cloud
- Récupérer les fichiers Python du dépôt et les modifier pour votre projet
- Générer des données synthétiques et exécuter le pipeline
- Vérifier les résultats dans BigQuery
Enfin, vous pourrez prendre le temps de réfléchir à ce que vous avez appris dans cet atelier et à la manière dont vous pourriez traiter vos propres cas d'utilisation avec des données en flux continu en répondant aux questions du journal de l'atelier.
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Des identifiants temporaires vous sont fournis pour vous permettre de vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- Vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome).
Remarque : Ouvrez une fenêtre de navigateur en mode incognito (recommandé) ou de navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
- Vous disposez d'un temps limité. N'oubliez pas qu'une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Remarque : Utilisez uniquement le compte de participant pour cet atelier. Si vous utilisez un autre compte Google Cloud, des frais peuvent être facturés à ce compte.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, une boîte de dialogue s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous trouverez le panneau "Détails concernant l'atelier", qui contient les éléments suivants :
- Le bouton "Ouvrir la console Google Cloud"
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée si vous utilisez le navigateur Chrome).
L'atelier lance les ressources, puis ouvre la page "Se connecter" dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte.
-
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
{{{user_0.username | "Username"}}}
Vous trouverez également le nom d'utilisateur dans le panneau "Détails concernant l'atelier".
-
Cliquez sur Suivant.
-
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
{{{user_0.password | "Password"}}}
Vous trouverez également le mot de passe dans le panneau "Détails concernant l'atelier".
-
Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis pour l'atelier. Ne saisissez pas ceux de votre compte Google Cloud.
Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés.
-
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais sans frais.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Pour accéder aux produits et services Google Cloud, cliquez sur le menu de navigation ou saisissez le nom du service ou du produit dans le champ Recherche.

Tâche 1 : Configurer des variables d'environnement dans Cloud Shell
Dans cette tâche, vous allez configurer des variables d'environnement dans Cloud Shell.
-
Ouvrez Cloud Shell.
-
Vous devez autoriser son utilisation, car c'est la première fois que vous utilisez Cloud Shell dans cet atelier. Pour cela, cliquez sur Autoriser dans la fenêtre pop-up.
-
Exécutez les commandes suivantes.
export PROJECT_ID="{{{project_0.project_id|set at lab start}}}"
export REGION="{{{project_0.default_region|set at lab start}}}"
export BUCKET_NAME="{{{project_0.project_id|set at lab start}}}-bucket"
-
Exécutez les commandes ci-dessous pour vérifier que les variables sont stockées.
echo ${PROJECT_ID}
echo ${REGION}
echo ${BUCKET_NAME}
Tâche 2 : Créer les ressources cloud
Dans cette tâche, vous allez créer les ressources cloud, y compris le sujet et l'abonnement Pub/Sub, ainsi que l'ensemble de données BigQuery à l'aide de Cloud Shell.
Créer les ressources cloud
Toujours dans Cloud Shell :
-
Exécutez la commande suivante pour créer le sujet Pub/Sub.
gcloud pubsub topics create esports_events_topic
-
Exécutez la commande suivante pour créer l'abonnement Pub/Sub.
gcloud pubsub subscriptions create esports_events_topic-sub --topic=esports_events_topic
-
Exécutez la commande suivante pour créer l'ensemble de données BigQuery.
bq --location=US mk --dataset esports_analytics
Confirmer la création des ressources
-
En haut de la console, vous trouverez une fonction de recherche. Saisissez Pub/Sub, puis cliquez sur Pub/Sub dans les options affichées. Les sujets Pub/Sub s'affichent, y compris esports_events_topic.
-
Cliquez sur esports_events_topic, qui est l'ID du sujet. L'onglet "Abonnements" s'affiche pour le sujet, et l'abonnement esports_events_topic-sub est répertorié. Cela confirme que vous avez bien créé le sujet et l'abonnement.
-
Revenez à la fonction de recherche en haut de la console. Saisissez BigQuery, puis cliquez sur BigQuery dans les options proposées. La page "Bienvenue dans BigQuery Studio" s'affiche avec un pop-up Bienvenue sur BigQuery dans la console Cloud.
-
Cliquez sur OK.
-
Dans le volet "Explorateur", développez votre projet.
-
L'ensemble de données esports_analytics s'affiche en bas de la liste. Cela confirme que vous avez bien créé l'ensemble de données BigQuery.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer les ressources cloud
Tâche 3 : Récupérer les fichiers Python et les configurer
Vous allez maintenant utiliser wget dans Cloud Shell pour récupérer les fichiers Python à partir d'un bucket Cloud Storage public. Puis, vous ouvrirez les fichiers dans l'éditeur Cloud Shell et utiliserez la fonctionnalité Code Assist de Gemini pour expliquer le fonctionnement de chaque fichier. Enfin, vous utiliserez l'éditeur Cloud Shell pour configurer les fichiers avec les détails de votre projet et votre bucket Cloud Storage.
Récupérer les fichiers Python
-
Revenez dans Cloud Shell.
-
Exécutez la commande suivante pour revenir au répertoire d'accueil.
cd ~
-
Créez le répertoire esports et accédez-y.
mkdir esports
cd esports
-
Récupérez les fichiers Python à l'aide des commandes wget ci-dessous.
wget https://storage.googleapis.com/spls/gsp1298/esports-simulation.py
wget https://storage.googleapis.com/spls/gsp1298/esports-pipeline.py
Le terminal confirme que les fichiers ont été téléchargés.
Utiliser Code Assist pour obtenir des explications sur le rôle du fichier Python
-
Cliquez sur le bouton "Ouvrir l'éditeur" dans Cloud Shell. L'éditeur Cloud Shell s'ouvre. Le volet Gemini Code Assist s'affiche également.
-
Fermez l'onglet du tutoriel.
-
Dans le volet "Explorateur", développez le dossier esports. Les fichiers Python s'affichent.
-
Ouvrez le fichier esports-simulation.py.
-
En haut à droite du fichier, cliquez sur la flèche à côté de Gemini  .
.
-
Cliquez sur Sélectionner un projet Gemini Code Assist afin de sélectionner le projet à utiliser pour Gemini. Dans la liste, sélectionnez l'ID de projet .
-
Dans la partie inférieure du volet Gemini Code Assist, un champ permet de saisir un prompt, avec la mention "Demander à Gemini". Saisissez le prompt suivant :
Review the code in the file esports-simulation.py. Explain what this code does.
Vous constatez que Code Assist explique en détail ce que fait le code. Dans les grandes lignes, le code simule un match d'e-sport et publie les événements dans un sujet Google Cloud Pub/Sub.
-
Utilisez maintenant la même méthode pour expliquer ce que fait le fichier esports-pipeline.py avec ce prompt.
Review the code in the file esports-pipeline.py. Explain what this code does.
Temps de réflexion
- Compte tenu de vos données et de vos cas d'utilisation, réfléchissez à la façon dont vous utiliseriez Python pour générer des données synthétiques ou collecter des données à partir de vos applications, puis publier ces données en tant que messages Pub/Sub dans un sujet de votre propre workflow de développement. Notez vos réponses dans le journal de l'atelier.
Remarque : Gemini a aidé le développeur à créer le fichier esports-simulation.py. Pensez à Gemini pour générer des données de flux synthétiques avec Python pour vos projets, et à Code Assist pour vous aider à expliquer votre code et à résoudre les problèmes.
-
Décrivez avec vos propres mots le rôle du fichier esports-pipeline.py.
-
En tenant compte de vos données et de vos cas d'utilisation, réfléchissez à la façon dont vous utiliseriez un pipeline Dataflow pour consommer des messages Pub/Sub, transformer les données qu'ils contiennent et stocker les résultats dans BigQuery.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Récupérer les fichiers Python et les configurer
Configurer les fichiers pour votre projet et votre bucket
Toujours dans le fichier esports-pipeline.py :
-
Vers la ligne 11, définissez la variable PROJECT_ID avec l'ID de votre projet. Vous pouvez trouver cette information en haut de la console Google Cloud ou simplement remplacer la ligne par le code ci-dessous.
PROJECT_ID = "{{{project_0.project_id|set at lab start}}}"
-
Vers la ligne 18, définissez la variable GCS_TEMP_LOCATION avec le nom de votre bucket Cloud Storage (le nom du bucket qui vous a été fourni au départ). La ligne obtenue doit se présenter comme suit :
GCS_TEMP_LOCATION = "gs://{{{project_0.project_id|set at lab start}}}-bucket/temp"
-
Vers la ligne 19, définissez la variable REGION avec la région par défaut de l'atelier. Vous pouvez trouver cette information dans les détails du panneau de l'atelier, ou simplement remplacer la ligne par le code ci-dessous.
REGION = "{{{project_0.default_region|set at lab start}}}"
-
Enregistrez le fichier.
-
Revenez au fichier esports-simulation.py.
-
Vers la ligne 10, définissez la variable PROJECT_ID avec l'ID de votre projet. Comme pour l'autre fichier, remplacez simplement la ligne par le code ci-dessous.
PROJECT_ID = "{{{project_0.project_id|set at lab start}}}"
Remarque : Si vous ne modifiez pas les fichiers de votre projet, vous rencontrerez des erreurs d'exécution dans Cloud Shell lorsque vous exécuterez ces fichiers lors de la tâche suivante.
-
Enregistrez le fichier.
Tâche 4 : Générer des données synthétiques et exécuter le pipeline
Dans cette tâche, vous allez exécuter les fichiers Python pour générer les données synthétiques et exécuter le pipeline.
Installer les dépendances et exécuter le simulateur
-
Revenez au terminal Cloud Shell.
-
Vérifiez que vous êtes dans le répertoire d'accueil.
cd ~
-
Accédez au répertoire esports.
cd esports
-
Utilisez pip pour installer les dépendances, en particulier la bibliothèque Python pour Pub/Sub.
pip install google-cloud-pubsub
-
Exécutez le simulateur. Ce script s'exécutera en continu et enverra des événements à votre sujet Pub/Sub.
python3 esports-simulation.py
Vous verrez dans le terminal un résultat indiquant que des événements sont publiés. Gardez ce terminal ouvert et en cours d'exécution.
Confirmer que les messages sont publiés dans le sujet dans la console Pub/Sub
-
Utilisez la fonction de recherche en haut de la console. Cette fois, recherchez "Pub/Sub" et cliquez sur Pub/Sub dans la liste.
-
Cliquez sur esports_events_topic, qui est l'ID du sujet. L'onglet "Abonnements" s'affiche pour le sujet, et l'abonnement esports_events_topic-sub est répertorié.
-
Cliquez sur esports_events_topic-sub, qui correspond à l'ID de l'abonnement.
-
Sur la page des détails de l'abonnement esports_events_topic-sub, cliquez sur l'onglet MESSAGES. Un message s'affiche : "Cliquez sur "Extraire" pour afficher les messages et retarder temporairement leur distribution aux autres abonnés."
-
Cliquez sur EXTRAIRE. Si des messages s'affichent, cela confirme que les messages générés par le fichier esports-simulation.py sont bien reçus par Pub/Sub. N'hésitez pas à parcourir l'un des messages à l'aide du bouton Afficher le contenu.
Tenter d'exécuter le pipeline Dataflow
-
Ouvrez un nouvel onglet Cloud Shell. Cliquez sur l'icône + dans la barre du terminal Cloud Shell pour ouvrir un deuxième terminal.
-
Vérifiez que vous êtes dans le répertoire d'accueil.
cd ~
-
Accédez au répertoire esports.
cd esports
-
Installez les dépendances Python pour Dataflow (apache-beam). Dans le nouveau terminal, configurez un environnement virtuel et installez les bibliothèques requises.
python3 -m venv df-env
source df-env/bin/activate
pip install apache-beam[gcp]
-
Tentez de lancer le pipeline Dataflow. Exécutez le script de pipeline à l'aide de la commande ci-dessous. Assurez-vous d'avoir défini les variables d'environnement PROJECT_ID et BUCKET_NAME dans ce nouveau terminal.
export PROJECT_ID="{{{project_0.project_id|set at lab start}}}"
export BUCKET_NAME="{{{project_0.project_id|set at lab start}}}-bucket"
python3 esports-pipeline.py \
--project=$PROJECT_ID \
--region={{{project_0.default_region | Region}}} \
--runner=DataflowRunner \
--streaming \
--temp_location=gs://$BUCKET_NAME/temp \
--job_name=esports-leaderboard-pipeline
Cette commande envoie le job au service Dataflow. Le démarrage du job et le traitement des données prendront quelques minutes.
Cependant, à ce stade, vous verrez un avertissement et des erreurs comme ceux ci-dessous :
WARNING:apache_beam.options.pipeline_options:Bucket specified in staging_location has soft-delete policy enabled. To avoid being billed for unnecessary storage costs, turn off the soft delete feature on buckets that your Dataflow jobs use for temporary and staging storage. For more information, see https://cloud.google.com/storage/docs/use-soft-delete#remove-soft-delete-policy.
ERROR:apache_beam.runners.dataflow.dataflow_runner:2025-07-11T14:50:27.572Z: JOB_MESSAGE_ERROR: The Dataflow service agent cannot access the worker service account. Ensure that the Dataflow API is enabled for your project. In addition, verify that for the worker service account, the Dataflow service agent principal has the 'Cloud Dataflow Service Agent' role. To grant the role, see https://cloud.google.com/iam/docs/manage-access-service-accounts#view-access. On the Service Accounts page, select the worker service account, open the Permissions tab, and select 'Include Google-provided role grants' to verify roles. To learn more about service accounts, see https://cloud.google.com/dataflow/docs/concepts/security-and-permissions#permissions
Qu'est-ce que ça signifie ? Commençons par l'AVERTISSEMENT (WARNING).
L'avertissement indique que la fonctionnalité de protection par suppression réversible doit être désactivée pour le bucket utilisé dans cet atelier, -bucket. Nous vous recommandons de le désactiver. Vous trouverez ci-dessous les instructions pour cela.
Concernant l'ERREUR (ERROR). Voyons maintenant ce que signifie l'erreur.
Cette erreur a deux causes possibles.
-
L'API Dataflow n'est pas activée. Ici, nous l'avons activée pour vous au lancement de l'atelier. Vous pouvez le vérifier en accédant à "API et services".
-
En réalité, l'erreur se produit, car vous devez ajouter le rôle Agent de service Cloud Dataflow au compte de service de Cloud Compute. Vous trouverez ci-dessous les instructions pour effectuer cette tâche.
Désactiver la suppression réversible sur le bucket Cloud Storage
-
Utilisez la fonction de recherche en haut de la console. Recherchez "Cloud Storage" et cliquez sur l'option Cloud Storage dans la liste. La page Présentation s'affiche.
-
Cliquez sur Buckets. La page "Buckets" s'affiche et votre bucket, -bucket, figure dans la liste.
-
Cliquez sur le bucket -bucket. La page de détails du bucket s'affiche.
-
Cliquez sur Protection. Une liste d'options s'affiche, y compris Règle de suppression réversible (pour la récupération de données).
-
Cliquez sur Désactiver. Un pop-up Désactiver la règle de suppression réversible s'affiche.
-
Cliquez sur Confirmer. La règle de suppression réversible est désormais désactivée.
Ajouter le rôle d'Agent de service Cloud Dataflow
-
Utilisez la fonction de recherche en haut de la console pour accéder à IAM. La page IAM s'affiche.
-
Cliquez sur Comptes de service. La liste des comptes de service s'affiche. L'un des comptes de service répertoriés est celui de Compute Engine. Votre compte de service pour le service Compute Engine ressemblera à celui-ci :
655017706949-compute@developer.gserviceaccount.com
-
Pour ajouter le rôle d'Agent de service Cloud Dataflow à ce compte de service, commencez par cliquer sur Actions à côté.
-
Dans la liste des options proposées, cliquez sur Gérer les autorisations.
-
Sous "Gérer les autorisations des comptes de service", cliquez sur Gérer l'accès. Notez que le rôle Éditeur est déjà inclus.
-
Cliquez sur + Ajouter un autre rôle.
-
Utilisez l'option "Sélectionner un rôle". Recherchez et sélectionnez le rôle Agent de service Cloud Dataflow.
-
Cliquez sur Enregistrer.
-
Vérifiez que le rôle a été ajouté.
Exécuter le pipeline Dataflow
-
Revenez dans Cloud Shell.
-
Vérifiez que vous vous trouvez dans le deuxième onglet du terminal, celui qui permet d'exécuter le pipeline Dataflow (esports-pipeline.py).
-
Exécutez à nouveau la commande suivante :
export PROJECT_ID="{{{project_0.project_id|set at lab start}}}"
export BUCKET_NAME="{{{project_0.project_id|set at lab start}}}-bucket"
python3 esports-pipeline.py \
--project=$PROJECT_ID \
--region={{{project_0.default_region | Region}}} \
--runner=DataflowRunner \
--streaming \
--temp_location=gs://$BUCKET_NAME/temp \
--job_name=esports-leaderboard-pipeline
Cette fois, vous devriez voir un message indiquant que l'autoscaling est activé pour Dataflow Streaming Engine. Le nombre de nœuds de calcul varie entre 1 et 100, sauf si maxNumWorkers est spécifié.
Cela signifie que vous avez surmonté l'avertissement de suppression réversible et l'erreur de l'Agent de service Cloud Dataflow.
Accéder au service Dataflow et observer le pipeline
-
Utilisez la fonction de recherche en haut de la console pour rechercher et sélectionner le service Dataflow. La page "Jobs" s'affiche, avec deux jobs portant le même nom. L'un est en cours d'exécution et l'autre a échoué.
-
Cliquez sur le job en cours d'exécution. Le graphique du job s'affiche. En bas de la page, vous voyez le volet "Journaux".
-
Développez le volet "Journaux". Vous voyez les onglets "JOURNAUX DES JOBS" et "JOURNAUX DES NŒUDS DE CALCUL".
-
Cliquez sur JOURNAUX DES NŒUDS DE CALCUL.
-
Passez en revue les journaux fournis. Si vous voyez des journaux indiquant que les tables raw_events, player_score_updates et/ou team_score_updates ont été créées, vous pouvez passer à la tâche suivante.
Remarque : L'affichage de ces journaux pour les tables en cours de création peut prendre cinq à sept minutes.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Générer des données synthétiques et exécuter le pipeline
Tâche 5 : Vérifier les résultats dans BigQuery
Dans cette tâche, vous allez exécuter des requêtes SQL pour vérifier les résultats des messages traités. Pour cela, vous allez créer deux vues, puis les interroger pour afficher les classements des joueurs et des équipes. Vous prendrez également le temps de réfléchir à la façon dont Looker pourrait être utilisé pour améliorer les visualisations du classement.
Créer les vues dans BigQuery
-
Revenez dans BigQuery.
-
Dans l'explorateur, développez votre projet et sélectionnez l'ensemble de données esports_analytics.
-
Cliquez sur le signe + (plus) pour créer une requête.
-
Dans l'onglet Requête, saisissez la requête suivante :
-- Query 1: Create the Player Leaderboard View
-- This view finds the most recent score for each player and ranks them.
CREATE OR REPLACE VIEW `esports_analytics.player_leaderboard_live` AS
SELECT
-- Use the RANK() window function to calculate the rank in real-time
RANK() OVER (ORDER BY total_score DESC) as rank,
player_id,
total_score,
last_updated
FROM (
-- This subquery gets only the single most recent score for each player
SELECT
player_id,
total_score,
last_updated,
ROW_NUMBER() OVER (PARTITION BY player_id ORDER BY last_updated DESC) as rn
FROM
`esports_analytics.player_score_updates`
)
WHERE rn = 1;
-- Query 2: Create the Team Leaderboard View
-- This view finds the most recent score for each team and ranks them.
CREATE OR REPLACE VIEW `esports_analytics.team_leaderboard_live` AS
SELECT
-- Use the RANK() window function to calculate the rank in real-time
RANK() OVER (ORDER BY total_wins DESC) as rank,
team_id,
total_wins,
last_updated
FROM (
-- This subquery gets only the single most recent score for each team
SELECT
team_id,
total_wins,
last_updated,
ROW_NUMBER() OVER (PARTITION BY team_id ORDER BY last_updated DESC) as rn
FROM
`esports_analytics.team_score_updates`
)
WHERE rn = 1;
Cette requête crée deux vues : l'une pour le classement des joueurs et l'autre pour le classement des équipes. Elle trouvera les scores les plus récents du joueur et de l'équipe, et les classera en conséquence.
Exécuter une requête pour afficher le classement des joueurs
-
Cliquez sur le signe plus pour créer une requête.
-
Dans l'onglet Requête, saisissez la requête suivante :
SELECT * FROM `esports_analytics.player_leaderboard_live` ORDER BY rank;
Exécuter une requête pour afficher le classement des équipes
-
Cliquez sur le signe plus pour créer une requête.
-
Dans l'onglet Requête, saisissez la requête suivante :
SELECT * FROM `esports_analytics.team_leaderboard_live` ORDER BY rank;
Temps de réflexion
Utilisez votre journal pour répondre aux questions suivantes :
- Quel joueur est actuellement en tête ?
- Quelle équipe est en tête ?
Cliquez sur Vérifier ma progression pour valider l'objectif.
Vérifier les résultats dans BigQuery
Félicitations !
Vous avez généré des ressources Google Cloud pour prendre en charge votre pipeline Dataflow d'e-sport, y compris un sujet et un abonnement Pub/Sub, un ensemble de données BigQuery, des tables et des vues, ainsi que le pipeline lui-même à l'aide de données simulées générées à partir de scripts Python. Vous avez également utilisé Code Assist pour vous aider à expliquer le code de ces scripts. Vous êtes de plus en plus à l'aise avec Google Cloud au fil des jours, et vous pouvez vous servir de Gemini pour élargir vos connaissances et compétences en lien avec les workflows d'ingénierie des données.
Étapes suivantes et informations supplémentaires
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 11 août 2025
Dernier test de l'atelier : 11 août 2025
Copyright 2025 Google LLC. Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.






