GSP1298

Descripción general
Imagina que eres un ingeniero de datos de Cymbal Gaming. Tú y el equipo de desarrollo están creando un nuevo juego de eSports, "Galactic Grand Prix". El juego produce datos en tiempo real basados en partidas cara a cara entre dos jugadores de diferentes equipos. Por ejemplo, dos jugadores competirán en un evento. Se determina un ganador y, luego, se otorgan puntos al jugador y al equipo ganadores. Se te asignó la tarea de crear una solución para manejar estos datos transmitidos, aprovechando una canalización de Dataflow para transferir datos de Pub/Sub, transformarlos con código de Python y almacenar los resultados en tablas de BigQuery. Estas tablas se usarán para visualizar los resultados como paneles de jugadores y equipos.
Leíste que Pub/Sub, Dataflow y BigQuery podrían usarse para este tipo de caso de uso. También aprendiste que Gemini puede ayudarte en el proceso. Por ejemplo, si tienes dificultades mientras escribes una nueva consulta, podrías usar Code Assist para revisar y depurar tu código. Incluso también podría asistirte con sugerencias para resolver problemas. Usar estas funciones te ayudará a ser más independiente en tu trabajo y, quizás, hasta más eficiente. Sin embargo, no sabes cómo empezar.
Cuando inicies el lab, el entorno contendrá los recursos que se muestran en el siguiente diagrama.
Al final del lab, habrás usado la arquitectura para realizar varias tareas.
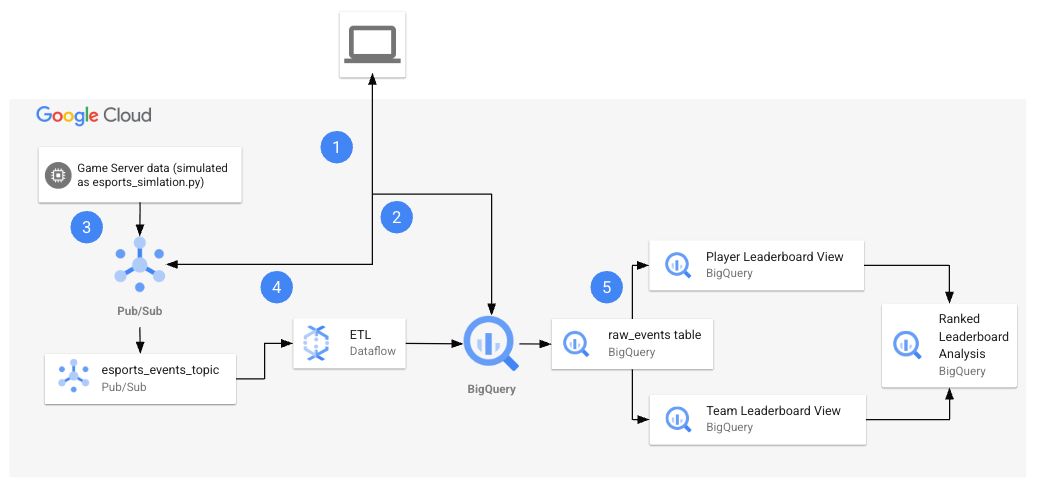
En la siguiente tabla, se proporciona una explicación detallada de cada tarea en relación con la arquitectura del lab.
| Tarea numerada |
Detalle |
| 1. |
Configurar variables de entorno en Cloud Shell |
| 2. |
Crear los recursos de la nube:
Usarás comandos de Cloud Shell para crear el tema y la suscripción de Pub/Sub, y el conjunto de datos de BigQuery. |
| 3. |
Recuperar los archivos de Python del repositorio:
En esta tarea, recuperarás los archivos de Python del repositorio y los configurarás para tu proyecto. |
| 4. |
Generar datos sintéticos y ejecutar la canalización:
Con los archivos de Python configurados para tu proyecto, ejecutarás los archivos para generar datos sintéticos y, luego, iniciarás la canalización. El archivo esports-simulation.py usa Python para generar mensajes continuos de Pub/Sub para eventos de juegos. Luego, puedes ejecutar el archivo esports-pipeline.py. Ejecutar este archivo inicia una canalización de Dataflow que transfiere los mensajes, los transforma y registra los resultados en las tablas raw_events, player score updates y team score updates en BigQuery. |
| 5. |
Verificar los resultados en BigQuery:
Ahora que consumiste y transformaste los datos, y escribiste los registros en las tablas de BigQuery, es hora de verificar los resultados. Ejecutarás consultas en cada tabla para analizar y ver los resultados. |
Objetivos
En este lab, aprenderás a realizar las siguientes tareas:
- Configurar las variables de entorno
- Crear los recursos de la nube
- Recuperar archivos de Python del repositorio y modificarlos para tu proyecto
- Generar datos sintéticos y ejecutar la canalización
-
Verificar los resultados en BigQuery
Por último, tendrás tiempo para reflexionar sobre lo que aprendiste en este lab y analizar cómo podrías abordar tus propios casos de uso con datos de transmisión, y responder preguntas en tu diario de lab.
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs cuentan con un temporizador que no se puede pausar. El temporizador, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar. Se recomienda el navegador Chrome.
Nota: Usa una ventana del navegador privada o de incógnito (opción recomendada) para ejecutar el lab. Así evitarás conflictos entre tu cuenta personal y la cuenta de estudiante, lo que podría generar cargos adicionales en tu cuenta personal.
- Tiempo para completar el lab (recuerda que, una vez que comienzas un lab, no puedes pausarlo).
Nota: Usa solo la cuenta de estudiante para este lab. Si usas otra cuenta de Google Cloud, es posible que se apliquen cargos a esa cuenta.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
-
Haz clic en el botón Comenzar lab. Si debes pagar por el lab, se abrirá un diálogo para que selecciones la forma de pago.
A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
- El botón para abrir la consola de Google Cloud
- El tiempo restante
- Las credenciales temporales que debes usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordena las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usar otra cuenta.
-
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}}
También puedes encontrar el nombre de usuario en el panel Detalles del lab.
-
Haz clic en Siguiente.
-
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}}
También puedes encontrar la contraseña en el panel Detalles del lab.
-
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud.
Nota: Usar tu propia cuenta de Google Cloud para este lab podría generar cargos adicionales.
-
Haz clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.
Nota: Para acceder a los productos y servicios de Google Cloud, haz clic en el menú de navegación o escribe el nombre del servicio o producto en el campo Buscar.

Tarea 1: Configura variables de entorno en Cloud Shell
En esta tarea, configurarás variables de entorno en Cloud Shell.
-
Abre Cloud Shell.
-
Debes autorizar el uso, ya que es la primera vez que usas Cloud Shell en este lab. Para ello, haz clic en Autorizar en la ventana emergente.
-
Ejecuta los siguientes comandos:
export PROJECT_ID="{{{project_0.project_id|set at lab start}}}"
export REGION="{{{project_0.default_region|set at lab start}}}"
export BUCKET_NAME="{{{project_0.project_id|set at lab start}}}-bucket"
-
Ejecuta los comandos que se indican a continuación para confirmar que las variables estén almacenadas.
echo ${PROJECT_ID}
echo ${REGION}
echo ${BUCKET_NAME}
Tarea 2: Crea los recursos en la nube
En esta tarea, crearás los recursos de la nube, incluidos el tema y la suscripción de Pub/Sub, y el conjunto de datos de BigQuery con Cloud Shell.
Crea los recursos en la nube
Mientras permaneces en Cloud Shell, haz lo siguiente:
-
Ejecuta el siguiente comando para crear el tema de Pub/Sub.
gcloud pubsub topics create esports_events_topic
-
Ejecuta el siguiente comando para crear la suscripción de Pub/Sub.
gcloud pubsub subscriptions create esports_events_topic-sub --topic=esports_events_topic
-
Ejecuta el siguiente comando para crear el conjunto de datos de BigQuery.
bq --location=US mk --dataset esports_analytics
Confirma la creación de recursos
-
En la parte superior de la consola, hay una función de búsqueda. Ingresa Pub/Sub aquí y haz clic en Pub/Sub en las opciones que se muestran. Verás una lista de temas de Pub/Sub, incluido esports_events_topic.
-
Haz clic en esports_events_topic, que es el ID del tema. Verás que aparece la pestaña Subscriptions para el tema y que se muestra la suscripción esports_events_topic-sub. Esto confirma que creaste el tema y la suscripción correctamente.
-
Regresa a la función de búsqueda en la parte superior de la consola. Ingresa BigQuery aquí y haz clic en BigQuery en las opciones que se muestran. Verás la página Te damos la bienvenida a BigQuery Studio con una ventana emergente para Te damos la bienvenida a BigQuery en la consola de Cloud.
-
Haz clic en Listo.
-
En el panel Explorador, expande tu proyecto.
-
Observa que, en la parte inferior de la lista, aparece el conjunto de datos esports_analytics. Esto confirma que creaste correctamente el conjunto de datos de BigQuery.
Haz clic en Revisar mi progreso para verificar el objetivo.
Crea los recursos en la nube
Tarea 3: Recupera los archivos de Python y configúralos.
Ahora usarás wget en Cloud Shell para recuperar los archivos de Python de un bucket público de Cloud Storage. Una vez recuperados, abrirás los archivos en el Editor de Cloud Shell y usarás la función de Code Assist de Gemini para explicar cómo funciona cada archivo. Por último, usarás el editor de Cloud Shell para configurar los archivos con detalles de tu proyecto y bucket de Cloud Storage.
Recupera los archivos de Python
-
Vuelve a Cloud Shell.
-
Ejecuta el siguiente comando para volver al directorio principal.
cd ~
-
Crea el directorio esports y navega hasta él.
mkdir esports
cd esports
-
Recupera los archivos de Python con los comandos wget que se indican a continuación.
wget https://storage.googleapis.com/spls/gsp1298/esports-simulation.py
wget https://storage.googleapis.com/spls/gsp1298/esports-pipeline.py
Verás una confirmación en la terminal de que los archivos se descargaron.
Usa Code Assist para explicar qué hace el archivo de Python
-
Haz clic en el botón Abrir editor en Cloud Shell. Verás que se abre el editor de Cloud Shell. También verás el panel de Gemini Code Assist.
-
Cierra la pestaña Explicación.
-
En el panel Explorador, expande la carpeta esports. Verás los archivos de Python.
-
Abre el archivo esports-simulation.py.
-
En la esquina superior derecha del archivo, haz clic en la flecha junto a Gemini  .
.
-
Haz clic en Seleccionar proyecto de Gemini Code Assist para seleccionar el proyecto que se usará para Gemini. En la lista, selecciona ID del proyecto.
-
En el panel de Gemini Code Assist, en la parte inferior, verás un lugar para ingresar una instrucción, donde dice "Pedirle a Gemini". Escribe la siguiente instrucción:
Revisa el código en el archivo esports-simulation.py. Explica qué hace este código.
Ves que Code Assist explica lo que hace el código en detalle. En un nivel alto, el código simulará un partido de eSports de eventos y los publicará en un tema de Google Cloud Pub/Sub.
-
Ahora usa el mismo proceso para explicar qué hace el archivo esports-pipeline.py con esta instrucción.
Revisa el código en el archivo esports-pipeline.py. Explica qué hace este código.
Momento de reflexión
- Teniendo en cuenta tus datos y casos de uso, piensa en cómo usarías Python para generar datos sintéticos o recopilar datos de tus aplicaciones y, luego, publicar estos datos como mensajes de Pub/Sub en un tema en tu propio flujo de trabajo de desarrollo. Registra tus respuestas en tu diario del lab.
Nota: Se usó Gemini para ayudar al desarrollador que creó el archivo esports-simulation.py. Considera usar Gemini para generar datos de transmisión sintéticos con Python para tus proyectos y ayuda a explicar y solucionar problemas de tu código con Code Assist.
-
Con tus propias palabras, ¿qué hace el archivo esports-pipeline.py?
-
Teniendo en cuenta tus datos y casos de uso, piensa en cómo usarías una canalización de Dataflow para consumir mensajes de Pub/Sub, transformar los datos en ellos y almacenar los resultados en BigQuery.
Haz clic en Revisar mi progreso para verificar el objetivo.
Recupera los archivos de Python y configúralos
Configura los archivos para tu proyecto y bucket
Mientras estás en el archivo esports-pipeline.py:
-
Alrededor de la línea 11, establece la variable PROJECT_ID en tu Project_ID. Puedes encontrarlo en la parte superior de la consola de Google Cloud o simplemente reemplazar la línea con el código que aparece a continuación.
PROJECT_ID = "{{{project_0.project_id|set at lab start}}}"
-
Alrededor de la línea 18, establece la variable GCS_TEMP_LOCATION con el nombre de tu bucket de Cloud Storage (el nombre del bucket que se te proporcionó en el lanzamiento). La línea resultante debería ser similar a lo siguiente:
GCS_TEMP_LOCATION = "gs://{{{project_0.project_id|set at lab start}}}-bucket/temp"
-
Alrededor de la línea 19, establece la variable REGION en tu región predeterminada del lab. Puedes encontrarlo en los detalles del panel del lab o simplemente reemplazar la línea por el siguiente código.
REGION = "{{{project_0.default_region|set at lab start}}}"
-
Guarda el archivo.
-
Vuelve al archivo esports-simulation.py.
-
Alrededor de la línea 10, establece la variable PROJECT_ID en tu Project_ID. Al igual que con el otro archivo, simplemente reemplaza la línea con el código que aparece a continuación.
PROJECT_ID = "{{{project_0.project_id|set at lab start}}}"
Nota: Si no modificas los archivos de tu proyecto, encontrarás errores en el tiempo de ejecución en Cloud Shell cuando ejecutes estos archivos en la siguiente tarea.
-
Guarda el archivo.
Tarea 4: Genera datos sintéticos y ejecuta la canalización
En esta tarea, ejecutarás los archivos de Python para generar los datos sintéticos y ejecutar la canalización.
Instala las dependencias y ejecuta el simulador
-
Regresa a la terminal de Cloud Shell.
-
Confirma que estás en el directorio principal.
cd ~
-
Navega al directorio esports.
cd esports
-
Usa pip para instalar las dependencias, específicamente la biblioteca de Python para Pub/Sub.
pip install google-cloud-pubsub
-
Ejecuta el simulador. Esta secuencia de comandos se ejecutará de forma continua y enviará eventos a tu tema de Pub/Sub.
python3 esports-simulation.py
Verás un resultado que indica que los eventos se publican en la terminal. Mantén esta terminal abierta y en ejecución.
Confirma que los mensajes se publiquen en el tema en la consola de Pub/Sub
-
Usa la función de búsqueda en la parte superior de la consola. Esta vez, busca Pub/Sub y haz clic en Pub/Sub en la lista.
-
Haz clic en esports_events_topic, que es el ID del tema. Verás que aparece la pestaña Subscriptions para el tema y que se muestra la suscripción esports_events_topic-sub.
-
Haz clic en esports_events_topic-sub, que es el ID de suscripción.
-
En la página de detalles de la suscripción esports_events_topic-sub, haz clic en la pestaña MENSAJES. Verás un mensaje que indica lo siguiente: "Haz clic en Extraer para ver los mensajes y demorar temporalmente la entrega de un mensaje a otro suscriptor".
-
Haz clic en EXTRAER. Si ves mensajes en esta lista, esto confirma que Pub/Sub está recibiendo los mensajes generados por el archivo esports-simulation.py. Si quieres, explora uno de los mensajes con el botón ver contenido.
Intenta ejecutar la canalización de Dataflow
-
Abre una pestaña nueva de Cloud Shell. Haz clic en el ícono + en la barra de la terminal de Cloud Shell para abrir una segunda terminal.
-
Confirma que estás en el directorio principal.
cd ~
-
Navega al directorio esports.
cd esports
-
Instala las dependencias de Python para Dataflow (apache-beam). En la nueva terminal, configura un entorno virtual y, luego, instala las bibliotecas requeridas.
python3 -m venv df-env
source df-env/bin/activate
pip install apache-beam[gcp]
-
Intenta iniciar la canalización de Dataflow. Ejecuta la secuencia de comandos de la canalización con el siguiente comando. Asegúrate también de haber configurado las variables de entorno PROJECT_ID y BUCKET_NAME en esta nueva terminal.
export PROJECT_ID="{{{project_0.project_id|set at lab start}}}"
export BUCKET_NAME="{{{project_0.project_id|set at lab start}}}-bucket"
python3 esports-pipeline.py \
--project=$PROJECT_ID \
--region={{{project_0.default_region | Region}}} \
--runner=DataflowRunner \
--streaming \
--temp_location=gs://$BUCKET_NAME/temp \
--job_name=esports-leaderboard-pipeline
Este comando envía el trabajo al servicio de Dataflow. El trabajo tardará unos minutos en iniciarse y comenzar a procesar los datos.
Sin embargo, en este punto verás una advertencia y errores como los siguientes:
ADVERTENCIA:apache_beam.options.pipeline_options:El bucket especificado en staging_location tiene habilitada la política de eliminación no definitiva. Para evitar cobros por costos de almacenamiento innecesarios, desactiva la función de eliminación
no definitiva en los buckets que usan tus trabajos de Dataflow para almacenamiento temporaly en etapa intermedia. Para obtener más información, consulta https://cloud.google.com/storage/docs/use-soft-delete#remove-soft-delete-policy.
ERROR:apache_beam.runners.dataflow.dataflow_runner:2025-07-11T14:50:27.572Z: JOB_MESSAGE_ERROR: El agente de servicio de Dataflow no puede acceder a la cuenta de servicio del trabajador. Asegúrate de que la API de Dataflow esté habilitada para tu proyecto. Además, verifica que, para la cuenta de servicio del trabajador, la principal del agente de servicio de Dataflow tenga el rol “Agente de servicio de Cloud Dataflow”. Para otorgar el rol, consulta https://cloud.google.com/iam/docs/manage-access-service-accounts#view-access. En la página Cuentas de servicio, selecciona la cuenta de servicio del trabajador, abre la pestaña Permisos y selecciona “Incluir asignaciones de roles proporcionadas por Google” para verificar los roles. Para obtener más información sobre las cuentas de servicio, consulta https://cloud.google.com/dataflow/docs/concepts/security-and-permissions#permissions
¿Qué significa esto? Primero, comencemos con la ADVERTENCIA.
La advertencia indica que el bucket usado en este lab, -bucket, debe tener inhabilitada la función de protección Borrar de forma no definitiva. Te recomendamos que la inhabilites. A continuación, te proporcionaremos instrucciones para hacerlo.
Con respecto al ERROR… Ahora, abordemos el ERROR… ¿Qué significa?
Este error tiene dos causas posibles.
-
La API de Dataflow no está habilitada. Sin embargo, al iniciar tu lab, habilitamos esta opción por ti. Para confirmarlo, ve a APIs y servicios.
-
La causa real del error es que debes agregar el rol Agente de servicio de Cloud Dataflow a la cuenta de servicio de procesamiento de Cloud. A continuación, incluiremos instrucciones para completar esta tarea.
Inhabilitar la función Borrar de forma no definitiva en el bucket de Cloud Storage
-
Usa la función de búsqueda en la parte superior de la consola. Busca Cloud Storage y haz clic en la opción Cloud Storage en la lista. Verás que aparece la página Descripción general.
-
Haz clic en Buckets. Verás que aparece la página Buckets y que tu bucket, -bucket, se muestra en la lista.
-
Haz clic en -bucket. Verás que aparece la página de detalles del bucket.
-
Haz clic en Protección. Verás una lista de opciones, que incluye Política de eliminación no definitiva (para la recuperación de datos).
-
Haz clic en Inhabilitar. Verás una ventana emergente para Inhabilitar la política de eliminación no definitiva.
-
Haz clic en Confirmar. Se inhabilitó la política de eliminación no definitiva.
Agrega el rol de agente de servicio de Cloud Dataflow
-
Usa la función de búsqueda en la parte superior de la consola para ir a IAM. Verás que aparece la página de IAM.
-
Haz clic en Cuentas de servicio. Verás que aparece la lista de cuentas de servicio. Una de las cuentas de servicio que se enumeran es la de Compute Engine. Tu cuenta de servicio para el servicio de Compute Engine se vería similar a la siguiente:
655017706949-compute@developer.gserviceaccount.com
-
Para agregar el rol de agente de servicio de Cloud Dataflow a esta cuenta de servicio, primero haz clic en Acciones junto a ella.
-
En la lista de opciones proporcionada, haz clic en Administrar permisos.
-
En Administrar permisos de cuenta de servicio, haz clic en Administrar acceso. Observa que el rol de Editor ya está incluido.
-
Haz clic en + Agregar otro rol.
-
Usa la opción Seleccionar un rol. Busca y selecciona el rol Agente de servicio de Cloud Dataflow.
-
Haz clic en Guardar.
-
Confirma que el rol se haya agregado.
Ejecuta la canalización de Dataflow
-
Vuelve a Cloud Shell.
-
Confirma que estás en la segunda pestaña de la terminal, la que se usa para ejecutar la canalización de Dataflow (esports-pipeline.py).
-
Vuelve a ejecutar el siguiente comando.
export PROJECT_ID="{{{project_0.project_id|set at lab start}}}"
export BUCKET_NAME="{{{project_0.project_id|set at lab start}}}-bucket"
python3 esports-pipeline.py \
--project=$PROJECT_ID \
--region={{{project_0.default_region | Region}}} \
--runner=DataflowRunner \
--streaming \
--temp_location=gs://$BUCKET_NAME/temp \
--job_name=esports-leaderboard-pipeline
Esta vez, deberías ver un mensaje que indica “El ajuste de escala automático está habilitado para Dataflow Streaming Engine. Los trabajadores se escalarán entre 1 y 100, a menos que se especifique maxNumWorkers".
Esto significa que superaste la advertencia de borrado de forma no definitiva y el error del agente de servicio de Cloud Dataflow.
Accede al servicio de Dataflow y observa la canalización
-
Usa la función de búsqueda en la parte superior de la consola para buscar y seleccionar el servicio de Dataflow. Verás que aparece la página Trabajos, con dos trabajos del mismo nombre. Uno se está ejecutando y el otro falló.
-
Haz clic en el trabajo en ejecución. Verás que aparece el gráfico de trabajo. En la parte inferior de la página, verás el panel Registros.
-
Expande el panel Registros. Verás pestañas para REGISTROS DE TRABAJO y REGISTROS DE TRABAJADOR.
-
Haz clic en REGISTROS DE TRABAJADOR.
-
Revisa los registros proporcionados aquí. Si ves registros que indican que se crearon las tablas raw_events, player_score_updates o team_score_updates, puedes pasar a la siguiente tarea.
Nota: Es posible que debas esperar entre 5 y 7 minutos para ver estos registros de las tablas que se están creando.
Haz clic en Revisar mi progreso para verificar el objetivo.
Genera datos sintéticos y ejecuta la canalización
Tarea 5: Verifica los resultados en BigQuery
En esta tarea, ejecutarás consultas de SQL para verificar los resultados de los mensajes procesados. Para lograrlo, crearás dos vistas y, luego, las consultarás para mostrar las tablas de clasificación de jugadores y equipos. También te tomarás un tiempo para reflexionar sobre cómo se podría usar Looker para mejorar las visualizaciones de la tabla de clasificación.
Crea las vistas en BigQuery
-
Vuelva a BigQuery.
-
En el explorador, expande tu proyecto y selecciona el conjunto de datos esports_analytics.
-
Haz clic en el signo + (más) para crear una consulta nueva.
-
En la pestaña Consulta, ingresa la siguiente consulta:
-- Query 1: Create the Player Leaderboard View
-- This view finds the most recent score for each player and ranks them.
CREATE OR REPLACE VIEW `esports_analytics.player_leaderboard_live` AS
SELECT
-- Use the RANK() window function to calculate the rank in real-time
RANK() OVER (ORDER BY total_score DESC) as rank,
player_id,
total_score,
last_updated
FROM (
-- This subquery gets only the single most recent score for each player
SELECT
player_id,
total_score,
last_updated,
ROW_NUMBER() OVER (PARTITION BY player_id ORDER BY last_updated DESC) as rn
FROM
`esports_analytics.player_score_updates`
)
WHERE rn = 1;
-- Query 2: Create the Team Leaderboard View
-- This view finds the most recent score for each team and ranks them.
CREATE OR REPLACE VIEW `esports_analytics.team_leaderboard_live` AS
SELECT
-- Use the RANK() window function to calculate the rank in real-time
RANK() OVER (ORDER BY total_wins DESC) as rank,
team_id,
total_wins,
last_updated
FROM (
-- This subquery gets only the single most recent score for each team
SELECT
team_id,
total_wins,
last_updated,
ROW_NUMBER() OVER (PARTITION BY team_id ORDER BY last_updated DESC) as rn
FROM
`esports_analytics.team_score_updates`
)
WHERE rn = 1;
Esta consulta crea dos vistas: una para la tabla de clasificación de jugadores y otra para la tabla de clasificación de equipos. Encontrará las puntuaciones más recientes del jugador y del equipo, y los clasificará en consecuencia.
Ejecuta una consulta para mostrar la tabla de clasificación de los jugadores
-
Haz clic en el signo más para crear una consulta nueva.
-
En la pestaña Consulta, ingresa la siguiente consulta:
SELECT * FROM `esports_analytics.player_leaderboard_live` ORDER BY rank;
Ejecuta una consulta para mostrar la tabla de clasificación del equipo
-
Haz clic en el signo más para crear una consulta nueva.
-
En la pestaña Consulta, ingresa la siguiente consulta:
SELECT * FROM `esports_analytics.team_leaderboard_live` ORDER BY rank;
Momento de reflexión
Con tu diario, responde las siguientes preguntas:
- ¿Qué jugador está en primer lugar?
- ¿Qué equipo está actualmente en primer lugar?
Haz clic en Revisar mi progreso para verificar el objetivo.
Verifica los resultados en BigQuery
¡Felicitaciones!
Generaste recursos de Google Cloud para respaldar tu canalización de Dataflow de eSports, incluidos un tema y una suscripción de Pub/Sub, un conjunto de datos de BigQuery, tablas y vistas, y la canalización en sí con datos simulados generados a partir de secuencias de comandos de Python. También usaste Code Assist para que te ayude a explicar el código en estas secuencias de comandos. Cada día estás adquiriendo más confianza con Google Cloud y puedes usar Gemini para complementar tu conocimiento y tus habilidades con flujos de trabajo de ingeniería de datos.
Próximos pasos/Más información
Capacitación y certificación de Google Cloud
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Última actualización del manual: 11 de agosto de 2025
Prueba más reciente del lab: 11 de agosto de 2025
Copyright 2025 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.






